こんにちは!エンジニアの宮本です!
今回は CData Sync を使って、Salesforce から Google BigQuery へデータをレプリケーションする方法をご紹介いたします。
- CData Sync とは?
- CData Sync ができること
- Salesforce から Google BigQuery へのレプリケーション
- 差分更新対応について
- CData Sync の各種機能について
- 毎月のデータをテーブルにして保持
- 最後に
CData Sync とは?
クラウド/SaaS のデータをノンコーディングで直観的にDB にレプリケーション(複製)できるツールです。
基本的には「同期元のデータソースの設定」、「同期先DBの設定」、「同期先ジョブの設定」の3ステップでデータレプリケーションの設定が行えます。
また、一度接続先を設定してしまえば、さまざまなデータソースと DB の組み合わせを GUI で設定することが可能です。

CData Sync ができること
CData Sync は Saas、DB、テキストベースのファイルなどのデータソースを、データベースへレプリケーションすることは得意です。
例えば、同期先DBを BigQuery に指定した場合は、このような構成になります。
同期元と同期先の間に CData Sync が入るイメージです。その際、CData Sync が起動する場所はローカルでもクラウドでもどこでも大丈夫です。


ただし、 以下のような処理は向いていません。
* バイナリファイルの連携(単体のファイルを指定した場合は、ストアドを使って実現できます)
* SaaS への書き込み(現時点ではできません)
Salesforce から Google BigQuery へのレプリケーション
まずは、 Salesforce の標準オブジェクトである Account オブジェクトを、BigQuery へレプリケーションしてみようと思います。

今回使用するもの
- Salesforce のアカウント
- BigQuery のアカウント
- CData Sync (評価版もあります。インストール手順は下記に記載)
CData Sync のインストール
まずは下記URLよりインストーラーのダウンロードを行ってください。インストーラーは .NET版と Java版がありますが、今回は .NET版を使います。
https://www.cdata.com/jp/sync/
※リンク先にて画面右上に「ダウンロード」ボタンがありますので、そこからダウンロード画面へ進んでください。
基本的には「次へ」で進んでインストールを完了させてください。

まずはCData Sync 画面の「情報」タブからライセンス認証を行ってください。
評価版の方もここから認証を行います。

同期元データソースの接続設定
最初に「接続」タブより下記画面に遷移し、赤枠の「データソース」を選択し、Salesforceアイコンを選択します。

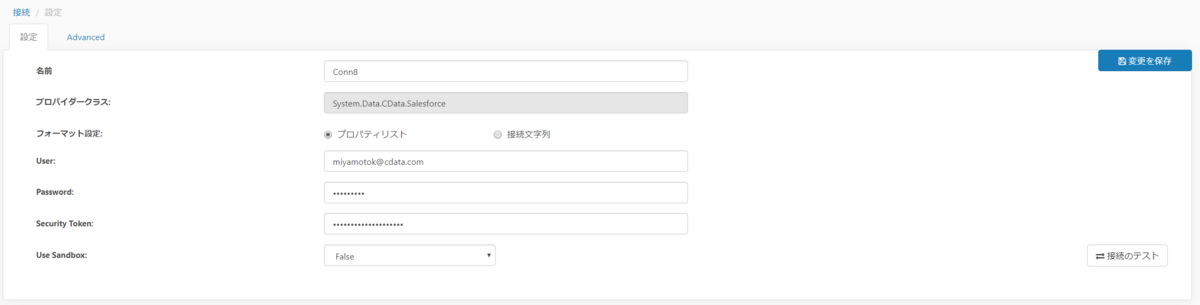
接続設定画面で接続情報を入力していきます。 接続するにあたり、プロキシ設定やログ出力設定、タイムアウト設定などさまざまな設定を行うことができますが、今回は最低限接続できる下記項目だけを設定していきます。
- User:Salesforce に登録しているアカウント
- Password:Salesforce に登録しているアカウントのパスワード
- Security Token:Salesforce に登録しているアカウントに対して発行されたセキュリティトークン
同期先DBの接続設定
同期元の接続情報の作成と作業内容は同じですが、「同期先」タブを選択し、そこに表示されているアイコンから選択して接続情報を入力してください。
今回は BigQuery を選択します。

データセットID、プロジェクトIDを入力したら、右下の「接続」ボタンを押します。

BigQuery へ接続するためのアカウントを選択します。

CData Sync から BigQuery への接続許可を行います。
右下の「Allow」ボタンをクリックします。

接続成功のメッセージが CData Sync の画面上部に表示されたら、保存ボタンをクリックします。
以上で接続先の設定は完了です。
同期ジョブの設定
ここでは "どこの同期元" から ”何のデータ” を ”どのように” 、"どこの同期先DB"へ同期させるかを設定していきます。
「ジョブ」タブを選択し、右端にある「ジョブを追加」ボタンをクリックします。

ソース、同期先に先ほど作成した Salesforce と BigQuery を接続情報に指定します。
※プルダウンで作成された接続情報が表示されます。

また、上記キャプチャの「テーブルを追加」ボタンを押すと、サブ画面にSalesforce のオブジェクトが表示されます。今回は Account オブジェクトを BigQuery に同期させますので、サブ画面上で選択します。

選択後、自動的にレプリケーションを行うクエリが作成されます。
クエリ:REPLICATE [Account]
右に表示されている時間やステータスは前回実行した際の内容が表示されています。

同期ジョブの実行
では、作成したクエリを実行してみます。
実行する場合は対象のクエリにチェックを入れてから「実行」ボタンをクリックしますと、同期処理が開始されます。

前回同期を行ったときに比べて差分がなかったので ”Records affected: 0” と表示されていますが、正常に同期処理が終了しました。

差分更新対応について
CData Sync では差分更新を対応しております。
毎回毎回全件を同期することなく、差分データのみの連携を行うことができるため、同期処理自体のパフォーマンスが格段にあがります。
ただし、現時点では全データソースに対応しているわけではございません。
CData Sync のサイトにありますデータソースに星マークがついているもののみが差分更新対象となっています。
https://www.cdata.com/jp/sync/connections/

CData Sync の各種機能について
先ほどご紹介した同期処理は、Salesforce の Account オブジェクトを何も加工せずに同期させましたが、実際は検索条件を付与したり、SQLの関数を使用したり、テーブルを結合して同期先に新しいテーブルを作成したりなど、クエリに条件を仕込むことができます。
毎月のデータをテーブルにして保持
データを分析する際、毎月のデータを比較したりすることはあると思いますが、集計した結果のデータを保持しているのみの場合、過去データに対してドリルダウンできませんよね。 CData Sync では 同期元・先の設定等は不要で、SaaS からデータを取得した場合でも、同期先に月ごとのテーブルを作成することができます。
設定方法は、対象のジョブを選択後、「イベント」タブに下記のようなコードを入れます。

<!-- Code goes here -->
<api:set attr="out.env:thismonth" value="[x|now|todate('yyyyMM')]" />
<api:push item="out"/>
あとはクエリに組み込んであげれば、年月が付与されたテーブルが自動的に作成されます。
例)REPLICATE [Account_'{env:thismonth}'] select * from [Account]

同期先の BigQuery に Account_年月 のテーブルが作成されたことが確認できました。

また同じ要領で年月カラムを追加し、自動的にレコードを蓄積することもできます。
例)REPLICATE [Account] SELECT Id, Name, '{env:thismonth}' AS [Snapshot_Date] FROM [Account]

最後に
今回は Salesforce から BigQuery へのレプリケーションについてご紹介しましたが、BigQuery の部分を AWS の RedShift に変更したり、Salesforce の部分を Marketo に変えたり、組み合わせは多種多様です。
CData Sync は他のCData Driver と同様に30日間の評価版がございますので、ぜひぜひ一度お試しいただければと思います。
【評価版URL】https://www.cdata.com/jp/sync/download/