はじめに
本資料は、CData Software Japanのハンズオン向けの資料です。本ドキュメントをもとに実機にCData Sync製品をインストールして手順に沿って操作する事で、Salesforceなどのクラウドサービスのデータやデータベースに格納されているデータをCSVファイルやBigQueryといったクラウドデータベースに同期する方法、加えてCData Sync の機能を理解して頂くことを目的としています。
今回の資料は以下記事から抜粋しています。ハンズオン終了後でも確認いただけます。 www.cdatablog.jp
ハンズオンの事前準備
本ハンズオンではVM環境に接続して実機でご確認いただく流れとなります。事前にこちらの手順でVMに接続できることを確認ください。
ハンズオンの内容
本ハンズオンでは以下の内容を行います。
本記事の目次
- はじめに
- ハンズオンの事前準備
- ハンズオンの内容
- CData Sync製品のインストール
- ライセンスのアクティベーション
- MySQL のデータをGoogle BigQuery にSync
- 1.MySQL 接続設定
- 2.BigQuery 設定
- 3.ジョブの作成
- 4.ジョブの実行
- Tips:差分更新
- おわり
- 補足記事
CData Sync製品のインストール

最初にCData Sync をダウンロードします。こちらからダウンロードページを表示してください。
右上にダウンロードボタンがありますのでクリックします。

今回はWinowsマシンのため、左側のWindowsマーク配下の「ダウンロード」をクリックします。

Eメールを入力し、ダウンロードボタンをクリックします。
そうしますと、 CDataSync.exe がダウンロードフォルダに入ってきますので、ダブルクリックしてインストールを開始します。
ライセンス契約書を確認後、次に進みます。
インストール先も支障がなければデフォルトのまま進みます。
デフォルトのまま次へ進みます。
デフォルトのまま次へ進みます。
ここまででインストールの準備が完了です。インストールボタンをクリックしてインストールを開始します。
以下の画面が表示されますと、インストールが完了となります。チェックボックスにチェックをつけたまま完了ボタンをクリックすることで、CDataSyncが起動されます。
起動するとWindowsのステータスバーにCData Sync のアイコンがこのように表示されます。

ライセンスのアクティベーション
スタートメニューからコンソールを開きます。

CDataSync にログインする際のパスワードを設定します。今回は「Password1」で設定します。
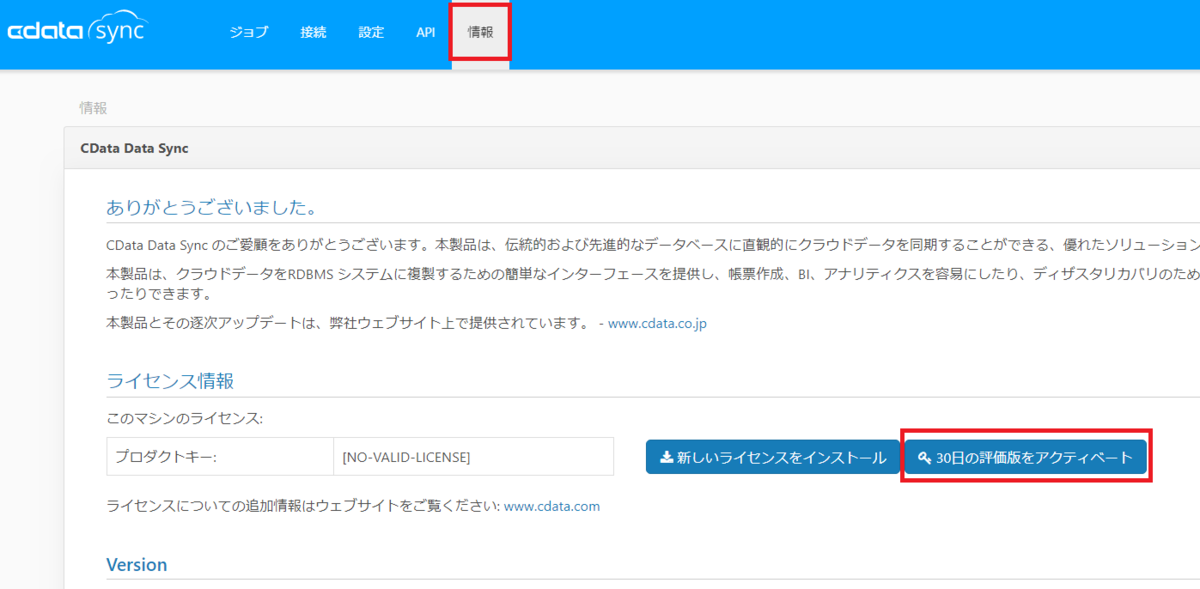
CData Sync にログイン後、ヘッダーの情報タブをクリックします。今回は赤枠の「評価版をアクティベート」をクリックします。
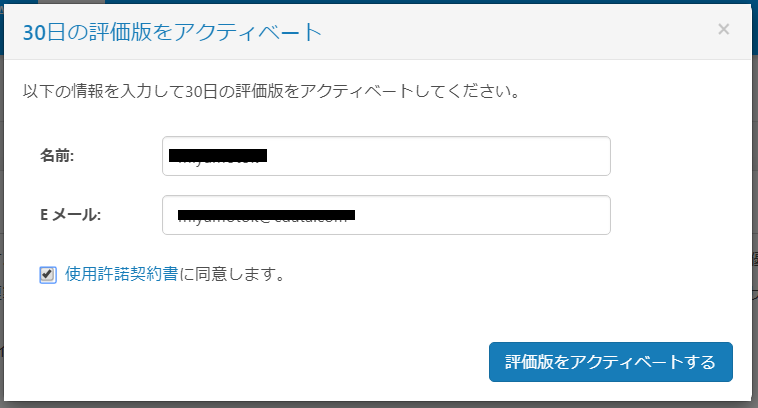
名前・Eメール、ソフトウェア使用許諾契約書にチェックを入れ、「評価版をアクティベートする」をクリックします。
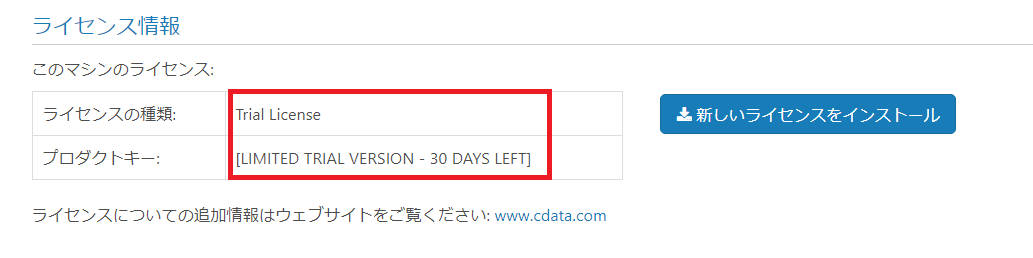
アクティベートが完了すると、赤枠のようにライセンスの種類、プロダクトキーに値がセットされます。なお、評価版は30日間まで無料でご利用いただけます。
MySQL のデータをGoogle BigQuery にSync

レプリケーション処理を構築します。
1.MySQL 接続設定
ヘッダーで「接続」をクリックし、「データソース」から「MySQL」アイコンをクリックします。

MySQL 接続設定画面が開かれます。名前を任意の名称(例:MySQL)に変更して、Server、Port、Database、User、Password を設定して、「接続のテスト」ボタンをクリックします。上段に「接続に成功しました。」のメッセージが出たら成功です。「変更を保存」ボタンをクリックして作成したコネクション情報を保存してください。データベースがローカルでもクラウドでも、設定内容は同様のものとなっています。

接続ができましたら右上の「変更を保存」をクリックし接続情報を保存します。
2.BigQuery 設定
同期先BigQuery の設定をします。
2-1.コネクタの更新
新しいバージョンのコネクタを取得します。 「接続」タブの「接続先の追加」より、「Add More」をクリックします。

「BigQuery」を検索し、ダウンロード&インストールをします。

Sync が再起動されますので、再度ログインします。
2-2.BigQuery 接続設定
BigQuery への接続を確立します。 「接続」タブの「同期先」を開き、「Google BigQuery」アイコンをクリックします。

BigQuery への接続設定画面が開かれます。 今回はサービスアカウントを使って接続するため、以下情報を入力します。
| Sync 設定名 | 設定内容 |
|---|---|
| Dataset Id | データセット名 |
| Project Id | プロジェクト名 |
| OAuth JWT Cert | キーファイルパス |
| OAuth JWT Cert Type | GOOGLEJSON |
| (Advanced)Auth Scheme | OAuthJWT |

入力が終わりましたら、「接続のテスト」をクリックし接続確認を行います。接続ができましたら右上の「変更を保存」をクリックし接続情報を保存します。
3.ジョブの作成
接続情報を使って、レプリケーションジョブを作成します。
「ジョブ」タブを開き、「ジョブを追加」をクリックします。

ジョブ作成画面で接続設定を指定し、作成ボタンをクリックします。
| Sync 設定画面 | 設定内容 |
|---|---|
| ジョブ名 | MySQL2BigQuery |
| ソース | MySQL |
| 同期先 | BigQuery |
ジョブの設定画面が開かれます。
テーブルを追加ボタンからレプリケートするテーブルを指定します。
今回は[sakila].[actor] テーブルを指定します。テーブルにチェックを入れたら、「テーブルを追加」ボタンで追加します。

4.ジョブの実行
作成したジョブを実行します。
実行するテーブルにチェックを入れ、「実行」ボタンをクリックします。

BigQuery にactor テーブルのデータがレプリケートされました。

Tips:差分更新
CData Sync では差分更新を行うことができます。対応しているデータソースはここから確認できます。
以下キャプチャの赤枠部分をご参照ください。ここが★マークになっているものが差分更新に対応しているデータソースとなります。

データソースがDB の場合は、クエリベースで差分情報を取得できます。
SELECT * FROM [account] WHERE [LastModifiedDate] > '2022-05-19'
参考記事:
おわり
以上でハンズオンは終了となります。お疲れ様でした。
補足記事
ログベースによる変更データキャプチャ(CDC)で PostgreSQL → BigQuery のレプリケーションをやってみた