こんにちは、テクニカルサポートエンジニアの宮本です。
今回は先日対応した全メンバーの申請書を取得する機能を使って、ドキュメントに入力した内容を定期的に DB に同期する方法をご紹介します。
シナリオ
コラボフロー上では注文書や請求書、経費精算書、日報などユースケースによって色々な種類の書類が申請できます。今回はその中でも実際にお問合せいただいたケースとして、日報の中身を DB に同期してというシナリオをやっていきます。

構成としては、各メンバーが申請している日報に入力されてるデータを
ETL/ELT ツールの CData Sync から取得して、BigQuery に定期的に同期していきます。
データソース
データソースとなる日報ですが、実際にはオリジナルでドキュメントを作成できるので細かく項目分けできるんですが、今回はコラボフローのWebサイトにあるシンプルな日報のサンプルフォーマットを使って作業時間や作業内容を抽出します。
同期先 DB について
なお、DB はクラウドDWH、オンプレRDB どちらでも連携することができますが、今回は BigQuery を選択しました。この辺はデータの活用方法によって選択する DB が変わってくるかと思います。
CData Sync をホスティング
CData Sync はインストール型になるので、オンプレ・クラウド、どこかしらのインスタンスにホスティングする必要がありますが、今回はローカルのWindows10 マシンから実行します。(Windows ServerやLinuxディストリビューションでももちろん可)
CData Sync とは
CData Sync は上記でも書いてあるようにセルフホスティング型の ETL/ELT ツールになります。
特徴としては同期ジョブを実行するまでのステップが少なく、容易に SaaS データを同期先 DB にレプリケートすることができます。
それではさっそくやっていきましょう。
必要なもの
- コラボフローのアカウント&APIKey
- CData Sync ※30日間の無償トライアルあり
- GCPアカウントと接続できる BigQuery のデータセットID
手順
まだ CData Sync をインストールしていない場合は、こちらのハンズオン記事を見ながら行っていただくとスムーズにインストールや操作感をイメージできますのでご参照ください。
コラボフローへの接続設定
Sync にアクセスしたら接続設定画面を開きます。初期設定ではコラボフローのコネクタは表示されていませんので、+Add More ボタンをクリックしてコネクタ追加を行います。

「collaboflow」と検索するとアイコンが表示されますのでクリックします。(途中までの入力でも表示されます)

ダウンロード&インストールをクリックします。

そうしますとコラボフローのコネクタがこのように追加されます。

ではそのままアイコンをクリックして接続設定を行います。
| 設定項目 | 設定内容 |
|---|---|
| 名前 | 接続情報名を設定 |
| user | コラボフロー へのログインユーザ名 |
| Profile Settings | コラボフローから取得したAPIKeyとアプリNo、インスタンス名を以下のように設定します。 APIKey=xxxxxxxx;AppCd=1;Instance=cdatajp1; |
※Instance、AppCdは以下で確認できます。
Instance: https://cloud.collaboflow.com/xxxxxx のxxxxxx部分
AppCd:コラボフローの「システム管理エリア > アプリ管理」で確認
詳しくはこちらの記事で。
コラボフロー 内のワークフロー情報をPower BI で可視化してみた - CData Software Blog

接続が完了後に保存を行ってコラボフローの接続設定が完了です。
BigQuery への接続設定
先ほどと同じように今度はBigQuery への接続設定を行います。

BigQuery へはユーザーアカウントによる認証のほか、サービスアカウントの認証も可能ですが、今回はユーザーアカウントでの認証を行います。
| 設定項目 | 設定内容 |
|---|---|
| 名前 | 接続情報名を設定 |
| Dataset Id | 同期先として使用するBigQuery のデータセットID |
| Project Id | 同期先として使用するBigQuery があるプロジェクトID |
入力し終えたら接続ボタンをクリックします。

CData Sync から対象のGoogleアカウントに接続して良いかというポップアップがきますので、続行ボタンをクリックして許可すると接続が完了します。

これで BigQuery への接続が完了です。
ジョブの作成
ではジョブを作成していきましょう。
ジョブを新規作成し、データソースにコラボフロー、同期先に BigQuery を選択してジョブを新規作成します。

次にテーブルを追加ボタンからテーブルリストを表示します。
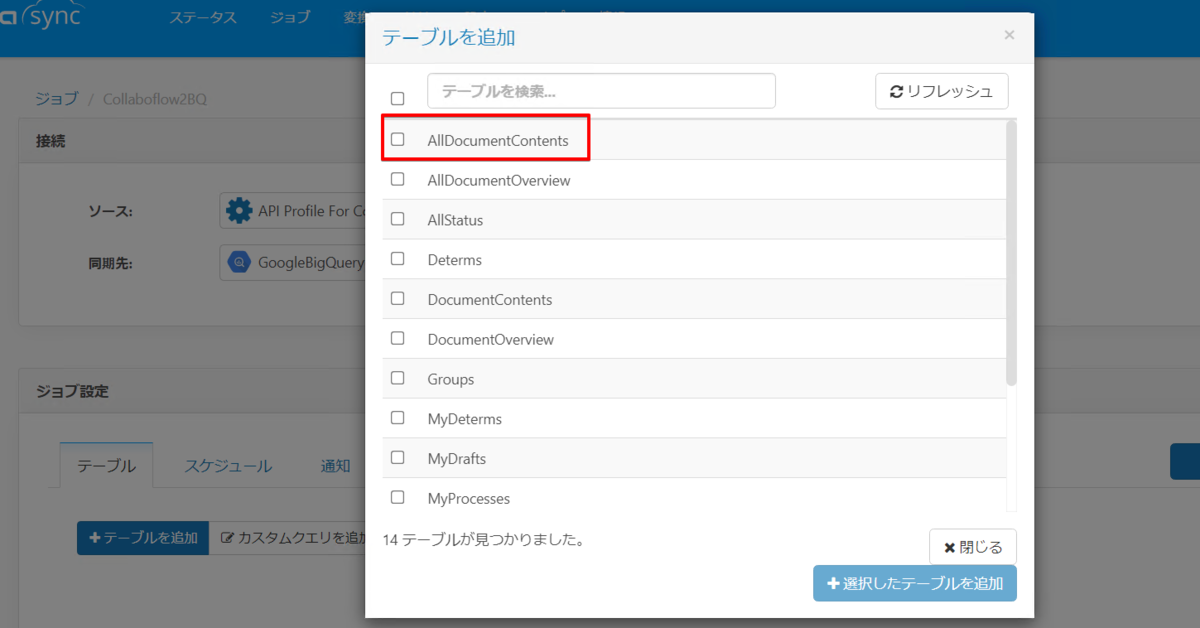 もしここでAllDocumentContents というテーブルが表示されていなかったら未対応のビルドを使用している可能性があります。その際は CData テクニカルサポートまでご連絡下さい。
もしここでAllDocumentContents というテーブルが表示されていなかったら未対応のビルドを使用している可能性があります。その際は CData テクニカルサポートまでご連絡下さい。
CData Software Japan - Support Form
テーブルを選択すると自動的にクエリがセットされます。この状態で対象のドキュメントがどのように取得できるか確認したいと思いますので、クエリ部分をクリックします。
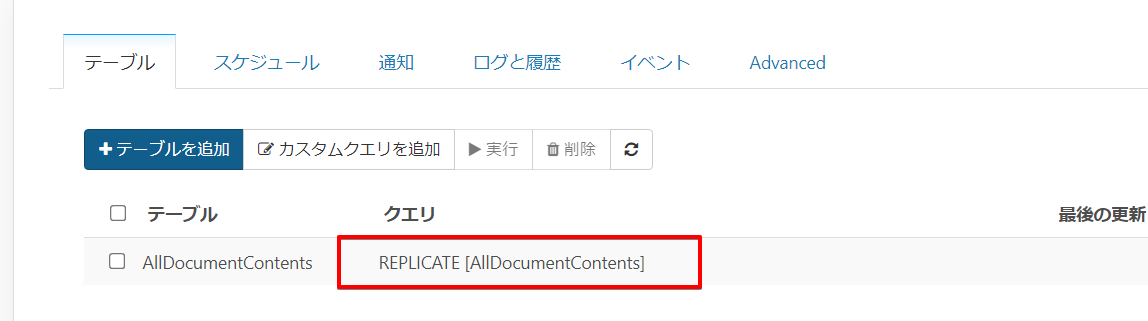
プレビュータブから Execute ボタンをクリックすると、事前にどのようなデータが連携できるかを確認することができます。
とは言え、今回は申請書の中身を連携したいのですが、そのデータは赤枠のContents というカラムにJSON形式で格納されています。

昨今の流れから「JSONのままで良いから生データのままデータストア先に保存したい」というケースであればこのままジョブを実行してもらえればOKです。
ただもう少し扱いやすい状態にしてから同期したいという場合は、JSON_EXTRACT という関数を使って値を取得していきます。
ドキュメントの値を取得する方法
今回使うドキュメントはコラボフローのWebサイトからダウンロードした日報を使っていきますが、扱うフォーマットはなんでも良いので読み替えていただければ他のドキュメントでもデータを取得することはできます。

下半分に入力されている課題や改善点について

実際には AllDocumentContents テーブルの Contents に上記ドキュメントに入力されている情報がこのように JSON で取得されます。
{ "table": [ { "fid3": { "display": true, "writable": false, "label": "A社:JDBC Driverの利用方法について", "value": "A社:JDBC Driverの利用方法について", "type": "text" }, "fid6": { "display": true, "writable": false, "label": "10:00", "value": "10:00", "type": "time" }, "fid7": { "display": true, "writable": false, "label": "12:00", "value": "12:00", "type": "time" }, "index": 1 }, { "fid3": { "display": true, "writable": false, "label": "B社:ODBC Driverの利用方法について", "value": "B社:ODBC Driverの利用方法について", "type": "text" }, "fid6": { "display": true, "writable": false, "label": "13:00", "value": "13:00", "type": "time" }, "fid7": { "display": true, "writable": false, "label": "15:00", "value": "15:00", "type": "time" }, "index": 2 }, { "fid3": { "display": true, "writable": false, "label": "C社:API Serverの利用方法について", "value": "C社:API Serverの利用方法について", "type": "text" }, "fid6": { "display": true, "writable": false, "label": "15:00", "value": "15:00", "type": "time" }, "fid7": { "display": true, "writable": false, "label": "17:00", "value": "17:00", "type": "time" }, "index": 3 } ], "fid1": { "display": true, "writable": false, "label": "1件/1時間でサポート対応を行う", "value": "1件/1時間でサポート対応を行う", "type": "textarea" }, "fid4": { "display": true, "writable": false, "label": "類似の問合せが多い", "value": "類似の問合せが多い", "type": "textarea" }, "fid5": { "display": true, "writable": false, "label": "複数回問合せを受けた内容はブログに書く", "value": "複数回問合せを受けた内容はブログに書く", "type": "textarea" } }
今回は以下のドキュメントの項目を取得します。対応する JSON は下記の通りになります。
| ドキュメント項目名 | JSON Path |
|---|---|
| 今日の目標 | fid1.value |
| 各時間帯 | fid6.value、fid7.value |
| 業務内容 | fid3.value |
| 課題・問題点 | fid4.value |
| 改善点 | fid5.value |
この対応表はフォーマットによって大きく変わりますので、ご利用されるフォーマットの情報を確認してから同じように対応するJSON の値を確認してください。
対象の項目と対応するJSONなんですが、クエリで指定する場合は JSON_EXTRACT という関数を使って定義します。
この JSON_EXTRACT では対象となる json と JSONパスをパラメータに指定します。例えば 今日の目標 を取得する場合は下記のようになります。
select JSON_EXTRACT(Contents,'$.fid1.value') AS "Today's Goal" from AllDocumentContents where Title = '日報'
フォーマットが変わるとJSON 構造も変わってしまいますが、だいたい同じ方法で取得できます。
では上記方法を駆使して対象の項目を取得してレプリケートするクエリを作成します。
replicate [daily_report] select DocumentId, DocumentNumber, EndDate, Error, FlowStatus, Link, ProcessesId, RequestDate, RequestGroup, RequestTitles, JSON_EXTRACT(RequestUser,'$.name') as UserName, Title, JSON_EXTRACT(Contents,'$.fid1.value') AS "Today's Goal", JSON_EXTRACT(Contents,'$.fid4.value') AS "Issue", JSON_EXTRACT(Contents,'$.fid5.value') AS "Improvement", JSON_EXTRACT(Contents,'$.table[0].fid3.value') AS "WorkDetails1", JSON_EXTRACT(Contents,'$.table[0].fid6.value') AS "StartTime1", JSON_EXTRACT(Contents,'$.table[0].fid7.value') AS "EndTime1", JSON_EXTRACT(Contents,'$.table[1].fid3.value') AS "WorkDetails2", JSON_EXTRACT(Contents,'$.table[1].fid6.value') AS "StartTime2", JSON_EXTRACT(Contents,'$.table[1].fid7.value') AS "EndTime2", JSON_EXTRACT(Contents,'$.table[2].fid3.value') AS "WorkDetails3", JSON_EXTRACT(Contents,'$.table[2].fid6.value') AS "StartTime3", JSON_EXTRACT(Contents,'$.table[2].fid7.value') AS "EndTime3", JSON_EXTRACT(Contents,'$.table[3].fid3.value') AS "WorkDetails4", JSON_EXTRACT(Contents,'$.table[3].fid6.value') AS "StartTime4", JSON_EXTRACT(Contents,'$.table[3].fid7.value') AS "EndTime4", JSON_EXTRACT(Contents,'$.table[4].fid3.value') AS "WorkDetails5", JSON_EXTRACT(Contents,'$.table[4].fid6.value') AS "StartTime5", JSON_EXTRACT(Contents,'$.table[4].fid7.value') AS "EndTime5" from AllDocumentContents where Title = '日報'
JSON を見て頂ければ時間と作業内容が複数取得できるのは確認できるかと思いますが、今回は とりあえず5行目までを取得するよう指定しています。(全行の場合はその分指定)
あとは日報以外にもコラボフロー上で申請はしていると思うので、ここでは日報だけを取得するようwhere 句で条件指定しています。
では上記クエリを改行をなくした状態で Sync に反映させますので、ジョブ設定画面で先ほど作成したクエリをクリックしてカスタムクエリを記述をオンにして反映します。
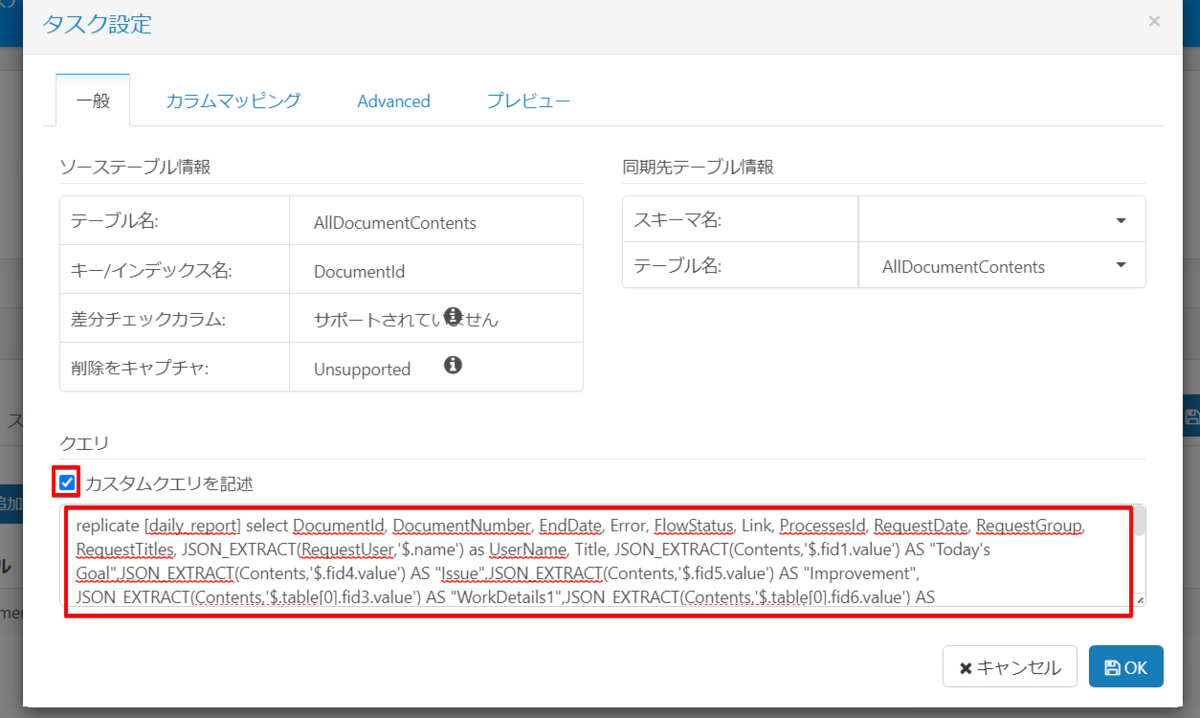
これでジョブ作成が完了しました。
ジョブ実行&結果確認
ではジョブを実行します。今回はスケジューリング実行ではなくアドホックに実行していきましょう。
クエリのチェックボックスをオンにして実行ボタンをクリックし、実行結果を確認します。
ジョブが正常終了すると画面上部に成功した旨のメッセージと右側にレプリケート件数などが表示されます。

ジョブ自体が正常に終了したということなので、BigQuery の指定したデータセットも確認してみると、テーブルが作成されレコードも入ってきているのが確認できました。
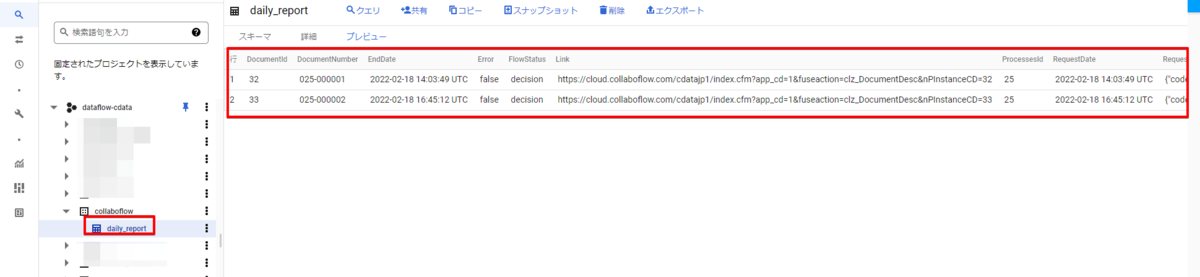
肝心なドキュメント内部の値も入ってきていますね。

おわりに
いかがでしたでしょうか。ドキュメント内部の値もJSON_EXTRACT 関数を用いることでデータを取得することができるようになりました。
今回使った CData Sync は30日間の無償トライアルが可能です。コラボフローで管理してるドキュメントの中身を DB に入れて色々活用したいと考えている場合は、CData Sync を使うことで簡単に実現できる可能性がありますので是非お試しいただけたらと思います。
コラボフローの全メンバーの申請情報なども取得可能です。詳細はこちらの記事をご参照ください。