
こんにちは。CData Software Japan の色川です。
翻訳サービスを利用する業務フロー自動化の一例として「CData ArcESB を使ってkintone のデータをDeepL で翻訳してSalesforce に連携する」方法を、こちらの記事でご紹介しました。 その後、ご相談を頂いたお客様と実際の業務におけるDeepL の活用状況について会話させて頂く中、割と最近DeepL の用語集が日本語にも対応したことで活用の幅が一層広がっている、と伺いました。たしかに製品名やサービス名など、独自の用語に変換したいニーズは多そうです。
ただし、こちらのDeepL ヘルプ記事によると、DeepL のWeb 翻訳ツールやアプリと、API の間では用語集に互換性がなく、API での翻訳で自分だけの用語集を利用するには用語集の作成もAPI で行う必要がありそうです。前回の記事で翻訳プロセスが自動化できたので、用語集の作成やメンテナンスもAPI で自動化して、翻訳プロセスに用語集を活用できたら嬉しいですよね。
そこで、この記事では「CData ArcESB を使ってCSV ファイルからDeepL に自分だけの用語集を作成する」方法をご紹介します。
- DeepL(API)
- CData ArcESB とは?
- この記事のシナリオ
- 必要なものと準備
- CSV ファイルからDeepL に自分だけの用語集を作成する
- 連携フローの実行と確認
- 登録された用語集を使ってみる
- この記事で作成したフロー(テンプレート)の入手
- おわりに
DeepL(API)
DeepL は最先端のAI技術で最高レベルの翻訳精度を実現しているサービスです。斬新な人工知能技術を駆使して比類ない翻訳品質を生み出すDeepLは、10億人以上に選ばれています。
CData ArcESB とは?
ファイル転送(MFT)とSaaSデータ連携をノーコードで実現できるデータ連携ツールです。ファイル・データベース・SaaS API、オンプレミスやクラウドにある様々なデータをノーコードでつなぐ事ができます。
この記事のシナリオ
用語集では翻訳元(source)と翻訳先(target)で対になる用語を指定します。こういった情報のメンテナンスはCSV のような形で編集できると楽ですよね。 そこでこの記事では「CSV ファイルからDeepL に自分だけの用語集を作成する」シナリオを作成します。

DeepL 用語集(Managing glossaries)API の概要
DeepL では2021年08月に用語集の機能が提供されました。 www.deepl.com
提供開始時点では残念ながら日本語への対応はありませんでしたが、この記事の時点では、既に日本語にも対応されています。翻訳が必要な業務での活用範囲が広がりますね!

https://support.deepl.com/hc/ja/articles/360021634540support.deepl.com
この記事の時点では、API で作成可能な用語集の最大数は1000まで。各用語集の最大サイズは10MB までに制限されています。またAPI の用語集には編集機能がないため、編集が必要な場合は、編集済みの用語集を新規に作成する形になるようです。詳しくはこちらのDeepL ヘルプ記事、およびAPI 技術資料を参考にしてください。 https://support.deepl.com/hc/ja/articles/4405021321746support.deepl.com
必要なものと準備
CData ArcESB は30日間フル機能を利用できるトライアルライセンスが提供されています。ぜひお手元で試してみてください。
製品のインストール等はこちらの記事を参考にしてください。
DeepL API 利用準備
認証キーの取得
DeepL API を利用するには、事前にDeepL のアカウント登録と認証キーの取得が必要です。アカウント登録やAPI の仕様については、こちらのガイドを参考にしてください。
アカウント登録したら、API コールに必要な認証キーを取得します。

用意したCSV ファイル
用語集では翻訳元(source)と翻訳先(target)で対になる用語を指定します。この記事では登録する用語データとして、このようなCSV ファイルを C:\Temp\DeepL\glossary.csv として用意しました。

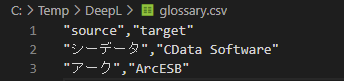
例えば「アークはシーデータの製品です。」というテキストを翻訳した時、用語集を指定しないと「ARC is a product of C-Data.」のように翻訳されますが、登録した用語集の利用を指定した時は「ArcESB is a product of CData Software.」になるイメージです。
CData ArcESB の基本的な使い方
CData ArcESB の起動方法や基本的なフローの作り方についてはこちらをご覧ください。
それでは実際に連携フローを作成していきます。
CSV ファイルからDeepL に自分だけの用語集を作成する
基本的な流れとしては「任意のディレクトリに保存したCSV ファイルを読み込んで、DeepL の用語集として登録(作成)」します。 DeepL の用語集API では、下記のように「登録した用語集のエントリをTSV 形式で一覧取得する」ことができますので、正しく登録されたかどうかを確認したい時はこういった機能を活用すると便利そうです。また登録した用語集は、登録時にレスポンスとして取得できる「glossary_id」を翻訳時に指定する形で利用します。
そこでこの記事では、登録した用語集を確認しやすいように&活用しやすいように、用語集を登録(作成)した後に、用語集エントリリスト取得API を実行して 登録された用語集の glossary_id.tsv の形でCSV ファイルと同じディレクトリに保存するようにしてみました。
このシナリオで作成する連携フローは以下のような流れになっています。
| コネクタ | 内容 | |
|---|---|---|
| 1 | File (Receive) | 任意のディレクトリに保存された用語集のもととするCSV ファイルを取得(受信) |
| 2 | CSV | 取得したCSV ファイルをフローで扱うためにXML ファイルに変換 |
| 3 | XML Map | 2 の用語集データを 4 の用語集への登録対象データとしてマッピング |
| 4 | REST (DeepL Creating a glossary) | DeepL の用語集作成API を実行 |
| 5 | REST (DeepL Listing entries of a glossary) | DeepL の用語集のエントリリスト取得API を実行 |
| 6 | File (Send) | 5 の取得内容を1 と同じディレクトリに保存(送信) |
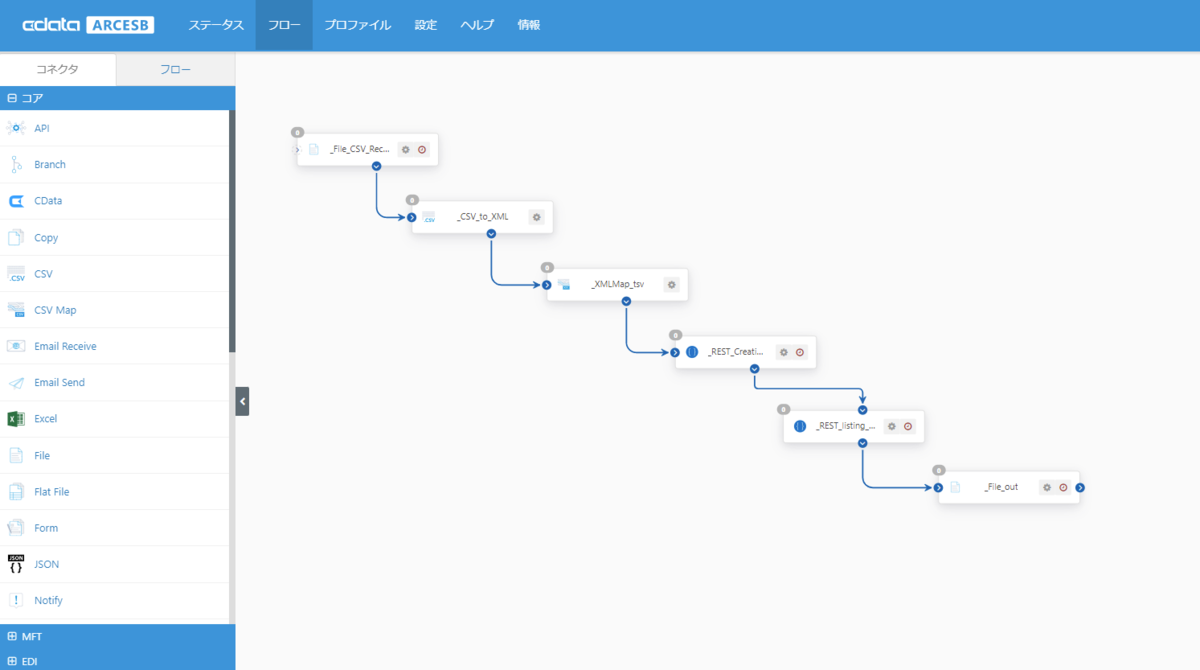
1. File (Receive)
最初にフローの起点となるFile コネクタ(kintone_Select)を配置し「任意のディレクトリに保存した(用語集のもととする)CSV ファイルを取得(受信)」します。コアカテゴリから「File コネクタ」を選択し、フローキャンバスへ配置します。
コネクタの設定で、取得対象ファイルを指定してください。パスに C:\Temp\DeepL、ファイルマスクに glossary.csv と指定しました。
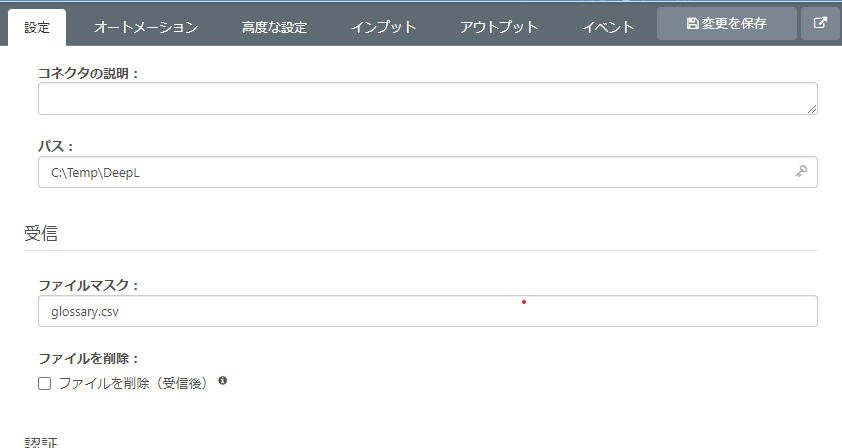
変更を保存 でコネクタ設定を保存します。アウトプットタブから受信を実行して、CSV ファイルが取得されることを確認します。

2. CSV
CData ArcESB のフローでは、流れるメッセージ基本的にXML 形式で扱います。この後のコネクタで扱いやすくするように、1. で取得したCSV ファイルをCSV コネクタでXML に変換します。コアカテゴリから「CSV コネクタ」を選択し、フローキャンバスへ配置します。

この記事ではヘッダ付きのCSV として用意しているため「Column headers present:」にチェックを入れます。他のプロパティは特に変更せず、デフォルトのままで利用します。

この後、XML Map でマッピングを施しますが、XML Map コネクタには、マッピングのソース(入力)と宛先(出力)の両方のサンプルXML 構造が必要です。テストファイルのアップロード機能を使用すると、CSV コネクタを使用してソースまたは宛先のXML テンプレートを簡単に生成できます。インプットタブの「テストファイルをアップロード」から、用意したCSV ファイルをアップロードしておきます。これでフローをつないだXML Map コネクタでCSV コネクタから出力されるスキーマを認識できるようになります。マッピングの際に便利になりますので、ぜひ活用してみてください。

テストファイルのアップロード機能については、こちらのヘルプトピックも参考にしてください。
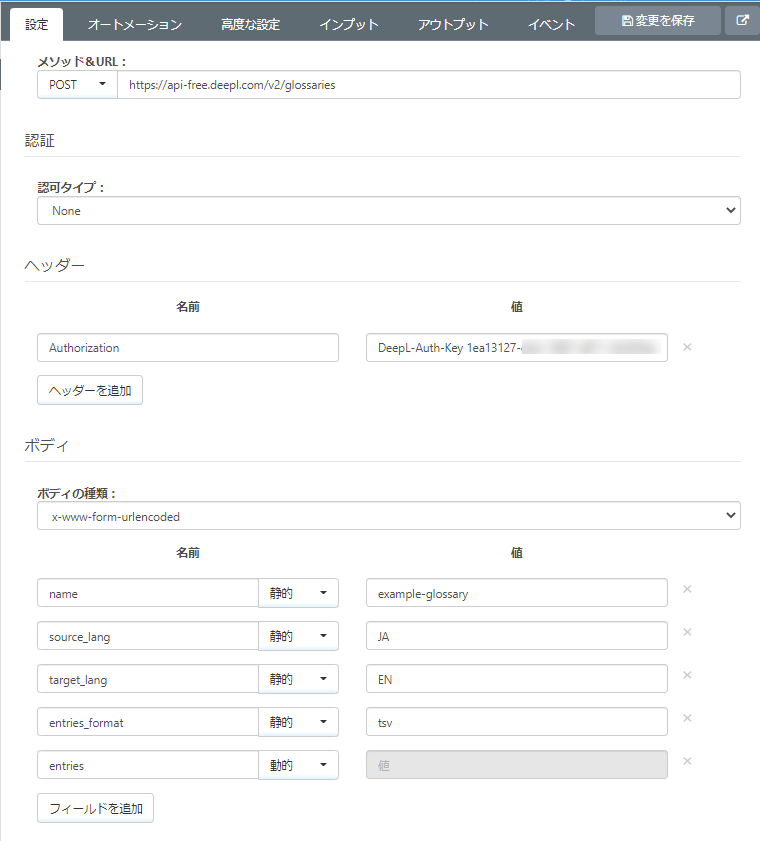
4. REST (DeepL Creating a glossary)
3 の前に、次にDeepL 用語集作成API の実行を設定します。コアカテゴリから「REST コネクタ」を選択し、フローキャンバスへ配置します。

メソッドは「POST」。URL にはDeepL の用語集作成API のガイドに従って指定します。
https://api-free.deepl.com/v2/glossaries
認証に必要なヘッダを設定します。
| 名前 | 値 |
|---|---|
| Authorization | DeepL-Auth-Key 事前準備で取得した認証キー |
ボディの種類は「x-www-form-urlencoded」。リクエストパラメータは以下のように設定します。
| 名前 | 静的/動的 | 値 |
|---|---|---|
| name | 静的 | 用語集につける任意の名前 |
| source_lang | 静的 | JA |
| target_lang | 静的 | EN |
| entries_format | tsv | |
| entries | 動的 | - |
entries を動的項目として設定します。動的項目はコネクタにインプットされるメッセージファイルの同名項目がマッピングされます。REST コネクタで動的として指定した「entries」はXML Map コネクタのマッピングで設定します。
DeepL の用語集作成API について、詳しくはこちらを参照してください。
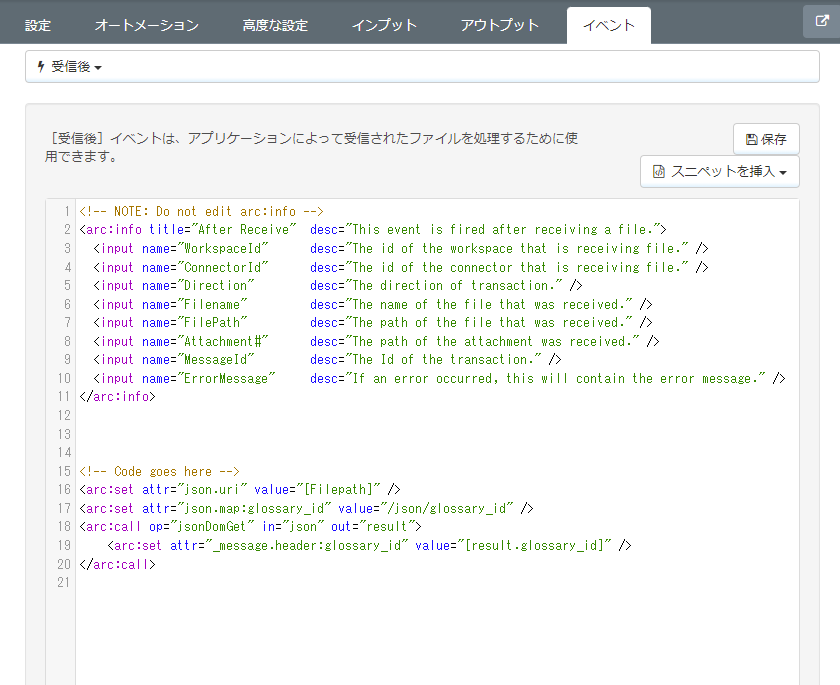
CData ArcESB ではフローを流れるメッセージ(データの流れ)にはメッセージヘッダ(メタデータ)が付与され、データの流れを追跡できるようになっています。この記事では、登録(作成)された用語集のId(glossary_id)を取得し、用語集の確認(エントリリストの取得)や保存するTSV ファイルのファイル名に使用するために、受信後のイベントで、API のレスポンスから glossary_id を取得し、メッセージヘッダに付与することで後続のコネクタで、glossary_id が利用できるようにします。
受信後イベントで以下のようなArc Script を設定します。
<arc:set attr="json.uri" value="[Filepath]" /> <arc:set attr="json.map:glossary_id" value="/json/glossary_id" /> <arc:call op="jsonDomGet" in="json" out="result"> <arc:set attr="_message.header:glossary_id" value="[result.glossary_id]" /> </arc:call>
CData ArcESB でのメッセージの仕組みは以下のドキュメントも参考にしてください。
3. XML Map
2 でXML ファイルに変換された用語集データを 4 の用語集への登録対象データとしてマッピングします。コアカテゴリから「XML Map コネクタ」を選択し、フローキャンバスへ配置します。2 から3 へ。3 から4 へ、フローをつなぎます。

2 のCSV コネクタではテストファイルのアップロードを実施してスキーマを生成しておきましたので、XML Map コネクタでソーススキーマが検出されます。4 のREST コネクタで動的項目として設定した属性はマッピング対象として検出されます。

DeepL のSupported Glossary Formats によると、用語集として登録したいエントリリストはTSV 形式の文字列としてタブや改行を含んだ文字列として生成し、用語集作成API のentries に設定する必要があるようです。

そのため、ここのマッピングでは、エントリのレコードを、ループ処理で _map コンテキストの変数に連結させた後、その文字列をループ終了後に entries にマッピングしました。

カスタムスクリプトの設定内容
<arc:set item="_map" attr="entries" value="[_map.entries | def() | concat('[xpath(source)]', '\t', '[xpath(target)]', '\n')]" />

entries の設定内容
<arc:info title="Custom Script" desc="The custom script."> <input name="FilePath" desc="The sending file path." /> <input name="XPath" desc="The current xpath in the loop." /> <input name="*" desc="The information of the current loop." /> </arc:info> <arc:set attr="result.text">[_map.entries]</arc:set>

このマッピングで使っている _map (Mapping Context) アイテム はArcESB で利用できるArcScript に用意されたビルトインアイテムの1つです。マッピングのある時点で計算を行い、マッピングの後半で参照する情報を保存するときなどに便利です。_map (Mapping Context) アイテムについてはこちらの記事も参考にしてください。
DeepL API でサポートされている用語集形式(Supported Glossary Formats)については、こちらのガイドを参考にしてください。
ここまでの流れで「CSV ファイルからDeepL に自分だけの用語集を作成する」ことができましたが、この記事では正しく登録されたかどうかを確認しやすいように、用語集のエントリリスト取得API を実行してTSV 形式で登録エントリリストを取得して、登録された用語集の glossary_id.tsv の形で用語集のもととするCSV ファイルのディレクトリに保存していきます。
5. REST (DeepL Listing entries of a glossary)
4 で登録(作成)した用語集のエントリリストをTSV 形式で取得します。コアカテゴリから「REST コネクタ」を選択し、フローキャンバスへ配置します。

メソッドは「GET」。URL にはDeepL の用語集エントリリスト取得API のガイドに従って指定します。
https://api-free.deepl.com/v2/glossaries/[_message.header:glossary_id]/entries
認証に必要な情報と、TSV 形式で取得するためのパラメータをヘッダに設定します。
| 名前 | 値 |
|---|---|
| Authorization | DeepL-Auth-Key 事前準備で取得した認証キー |
| Accept | text/tab-separated-values |
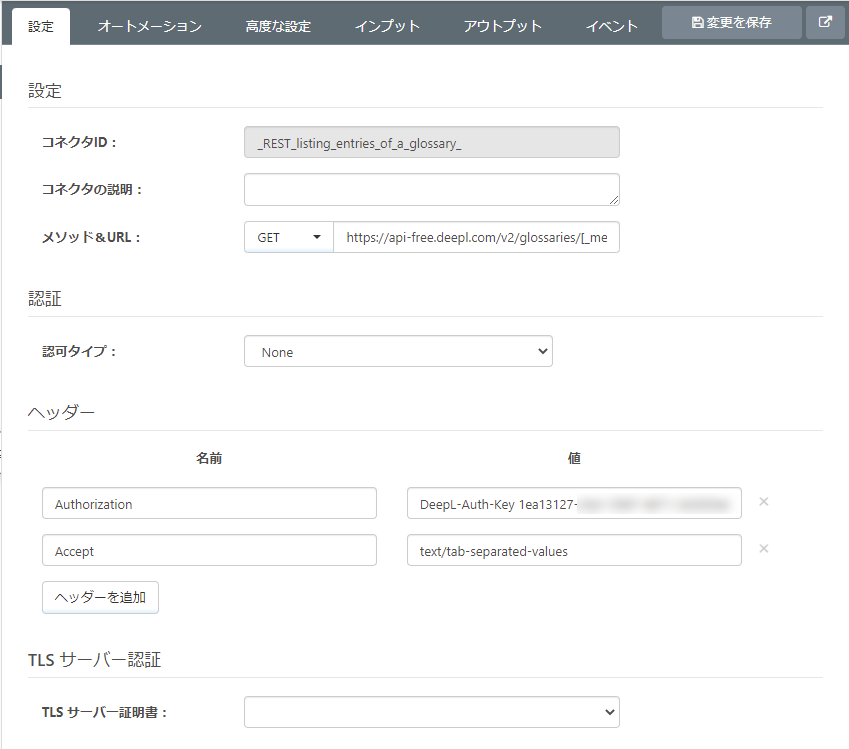
DeepL の用語集エントリリスト取得API について、詳しくはこちらを参照してください。
URL の中でArc Script が利用できるように「高度な設定 - URL 内のArcScript」で利用を許可します。また 登録された用語集の glossary_id.tsv のファイル名で保存できるように、「高度な設定 - ローカルファイルスキーム」で「%Header:glossary_id%.tsv」と指定します。

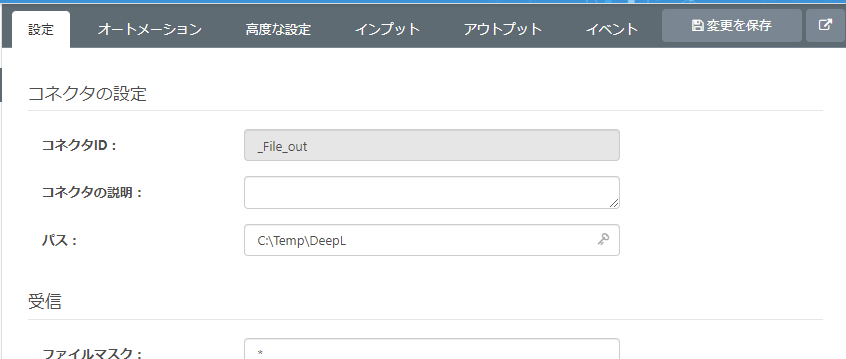
6. File (Send)
5 で取得した内容(TSV 形式で取得したエントリリストの情報)を1 と同じディレクトリに保存(送信)します。コアカテゴリから「File コネクタ」を選択し、フローキャンバスへ配置します。

コネクタの設定で、取得対象ファイルを指定してください。パスに C:\Temp\DeepL と指定しました。
これで「CSV ファイルからDeepL で自分だけの用語集を作成(して、作成した用語集のエントリリストを出力して保存)する」シナリオが出来あがりました。

連携フローの実行と確認
起点となるFile コネクタからフローを実行してみます。アウトプットタブから「受信」を実行します。

一定時間の後、CSV ファイルを用意したディレクトリに 登録された用語集の glossary_id.tsv のファイルが生成されていれば成功です。

中身を確認すると、登録されたエントリリストをTSV 形式で確認することができます。

登録された用語集を使ってみる
早速、登録された用語集を使ってみます。コアカテゴリから「REST コネクタ」を選択し、フローキャンバスへ配置します。

メソッドは「POST」。URL にはDeepL のテキスト翻訳API のガイドに従って指定します。
https://api-free.deepl.com/v2/translate?auth_key=`事前準備で取得した認証キー`
ボディの種類は「x-www-form-urlencoded」。リクエストパラメータは以下のように設定しました。
| 名前 | 静的/動的 | 値 |
|---|---|---|
| auth_key | 静的 | 事前準備で取得した認証キー |
| source_lang | 静的 | JA |
| target_lang | 静的 | EN |
| glossary_id | 静的 | 利用する用語集のId (TSV ファイルのファイル名に利用したglossary_id) |
| text | 静的 | アークはシーデータの製品です。 |

変更を保存 でコネクタ設定を保存します。アウトプットタブから受信を実行して、翻訳結果であるレスポンスを確認します。

期待通りに翻訳結果に登録した用語集が反映されていることが確認できました!

DeepL のテキスト翻訳API について、詳しくはこちらを参照してください。
この記事で作成したフロー(テンプレート)の入手
この記事で作成したフローについては、こちら からテンプレートとして使える arcflow がダウンロードできます。
ダウンロードしたarcflow は ワークスペースをインポート から登録できます。こちらのテンプレートの内、各コネクタでの接続情報などをお使いの環境に併せて編集して、ぜひ試してみてください。
おわりに
この記事のように数個のコネクタを繋ぎ合わせることで、DeepL の用語集登録や確認の流れを自動化することができました。DeepL API での用語集は編集機能がありませんが、用語集をCSV で編集できて、登録結果をTSV で確認できれば、用語集のメンテナンスも簡単ですね。
CData ArcESB はシンプルで拡張性の高いコアフレームワークに、豊富なMFT・EDI・エンタープライズコネクタを備えたパワフルな製品です。CData Drivers との組み合わせで250を超えるアプリケーションへの連携を実現できます。必要な連携を低価格からはじめられる事も大きな特長です。
皆さんのつなぎたいシナリオでぜひCData ArcESB を試してみてください。
お試しいただく中で何かご不明な点があれば、テクニカルサポートへお気軽にお問い合わせください。
この記事では CData ArcESB™ 2021 - 21.0.8188 を利用しています。