こんにちは。CData Software Japan エンジニアの宮本です。
今回は BigQuery へデータを登録する際の「ストリーミングインサート、DML、バルクロード」の 3つのインサート方法についてみていきたいと思います。
- それぞれのInsert パターンについて
- Insert パターン比較
- CData BigQuery Driver で試してみる
- CData BigQuery JDBC Driver でパフォーマンス比較
- おわりに
それぞれのInsert パターンについて
ストリーミングインサート
ストリーミングインサートは大量データを早く挿入する場合に最適な方法です。
特徴としては、他のインサートパターンよりも一般的には高速でインサートできることに加え、ジョブが完了しなくても随時参照できるというところになります。
ただしデータをBigQuery に送信してから 30 分以内の場合は、対象レコードへの Update や Delete などの DML ステートメントが利用できないようです。
https://cloud.google.com/bigquery/docs/reference/standard-sql/data-manipulation-language?hl=ja

また料金自体も他の手法より掛かるかもしれません。
https://cloud.google.com/bigquery/pricing?hl=ja
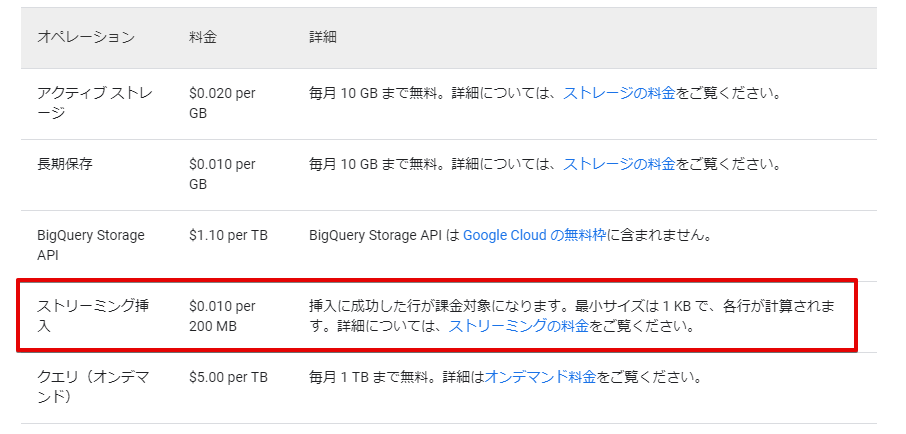
リアルタイム性が必要なければ、他の手段でも良いかもしれませんね。
DML
DMLは、データが正常に挿入されてすぐに更新できるようにする必要がある場合に最適です。逆に言うとエラー時は送信したレコードはBigQueryに登録されないという点ですね。ただ処理速度が遅いのに加えコストもかかりますが、登録したレコードがすぐに更新含めて利用可能であることが保証されているようです。
https://cloud.google.com/bigquery/docs/reference/rest/v2/jobs/query?hl=ja

料金についてはこのようになってますね。
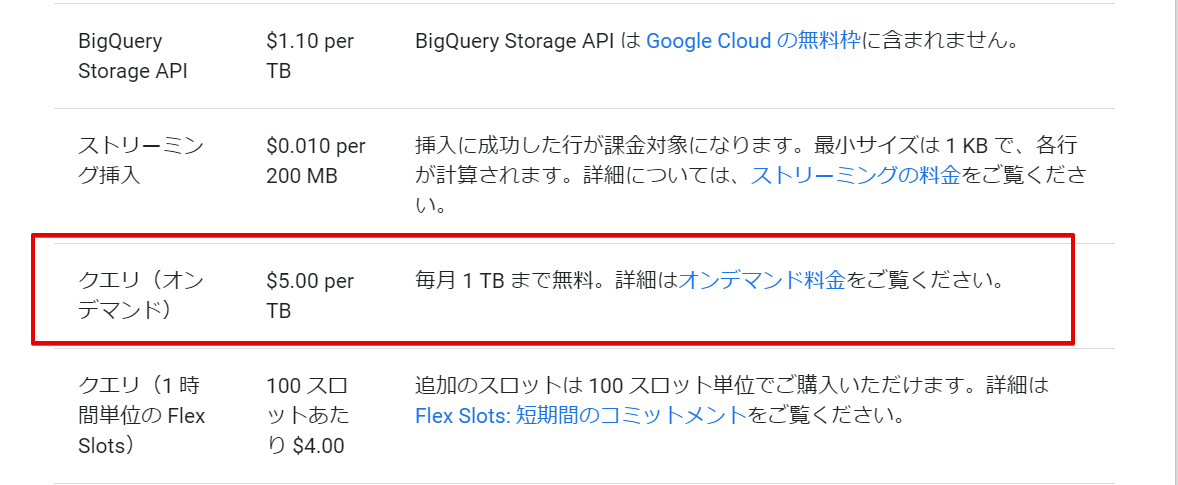
バルクロード
バルク処理として BigQuery API の API アップロードを利用することで、1回のリクエストでデータの挿入を行うことができます。パフォーマンスの点では他のInsert 方法と比べ、ちょうど中間的な位置でありますが、使用コスト自体が発生しないのがメリットです。またアップロードが処理されてからデータが挿入されるまでに遅延がありますが、ストリーミングモードよりははるかに小さいようですね。
Insert パターン比較
それぞれのパターンについて比較しました。ちなみに×と付与した箇所については悪いというわけではなく、他のInsert パターンと比較した結果という意味ですので、使い方次第ではパフォーマンスやコストでの差はあまりないです。
| Insert 方法 | パフォーマンス | 更新可能までの時間 | コスト | 正確性 |
|---|---|---|---|---|
| ストリーミング | 〇 | × | × | △ |
| DML | × | 〇 | △ | 〇 |
| バルク | △ | △ | 〇 | △ |
ストリーミングはパフォーマンスが良いので、ログをひたすら送り続けてリアルタイムで可視化するなどに向いてますよね。
DML は送信したレコードをBigQuery 上ですぐに加工したい、けど送信中に失敗したらロールバックしたいというときのケースでしょうか。用途によってはCloud SQL などもありかもですね。
バルクは全体的に平均的な処理となってます。Insert 時のコストを掛けたくないときに良さそうです。
CData BigQuery Driver で試してみる
CData では BIgQuery へ接続できるドライバーを JDBC 、ODBC、ADO.NET の他、Excel 向けプラグインなども提供しています。

その中で、今回は CData BigQuery JDBC Driver を使って確認していきます。
ドライバーのダウンロードは↓↓
https://www.cdata.com/jp/drivers/bigquery/jdbc/
JDBC Driver で Insert 方法の指定
CData BigQuery Driver では接続文字列の Insert Strategy オプションで切替が可能です。
切替時のパラメータ
| Insert 方法 | パラメータ |
|---|---|
| ストリーミング | streaming |
| DML | dml |
| バルク | batch |
デフォルトではストリーミングインサートで行うようになっていますが、例えば CData BigQuery JDBC Driver を使用している場合、このように接続文字列に"InsertStrategy=xxxxx" を追加でセットすることでDML やバルクでの方法に切り替えることができます。
jdbc:googlebigquery:InitiateOAuth=GETANDREFRESH;DatasetId=demo;ProjectID=test;InsertStrategy=dml
それぞれのリクエスト内容をみてみる
ストリーミングインサート
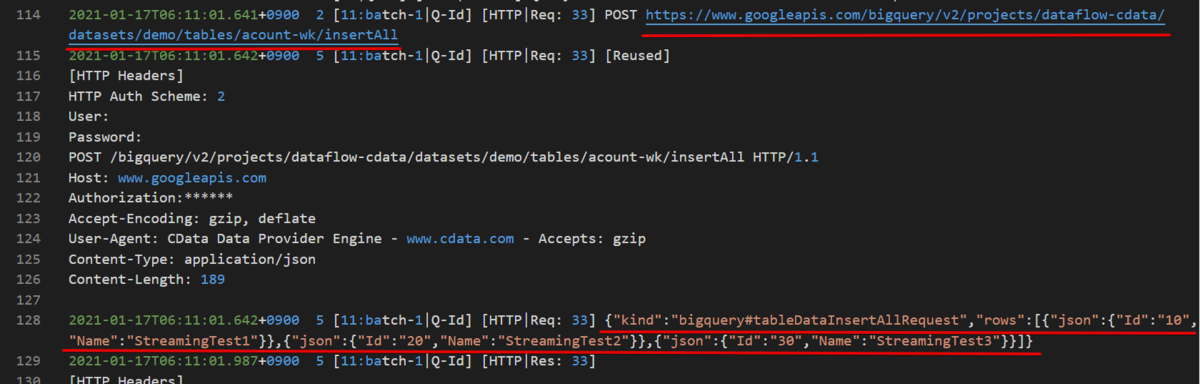
最初はストリーミングインサートからみていきます。接続文字列に InsertStrategy=streaming をセットして接続後、以下のSQL を実行してみます。
insert into [acount-wk] (Id,Name) values (10,StreamingTest1), (20,StreamingTest2), (30,StreamingTest3)
ストリーミングインサートの場合、insertAll メソッドを呼び出しているのが確認できます。送信レコードは json で body にセットされています。
DML
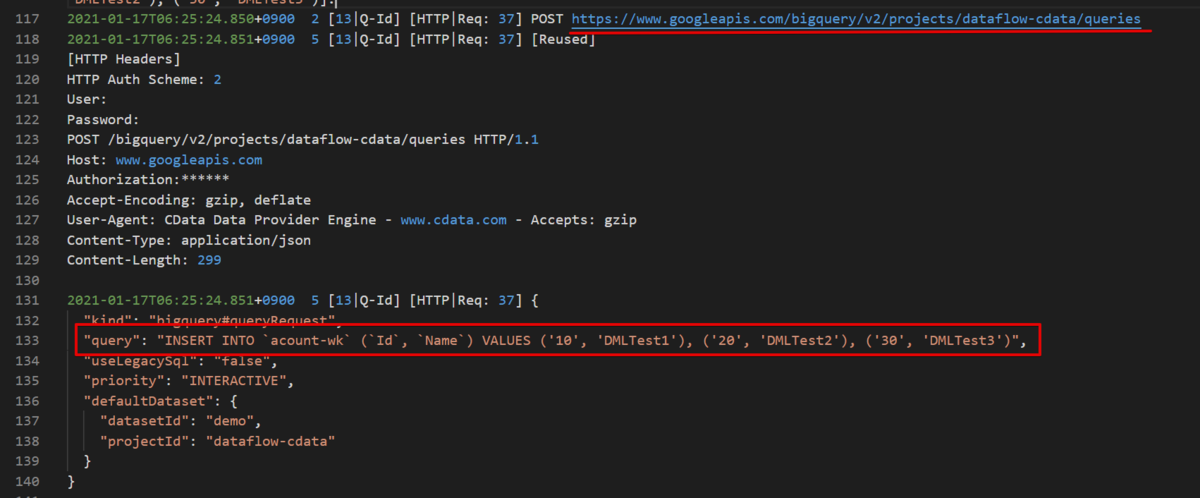
次に DML を確認してみるために、"InsertStrategy=dml" を指定し、同じようなSQL を実行してみます。
insert into [acount-wk] (Id,Name) values (10,DMLTest1), (20,DMLTest2), (30,DMLTest3)
今度は queries メソッドを呼び出し、json でレコードをセットするにではなく、insert 文でそのまま送っていますね。
バルクロード
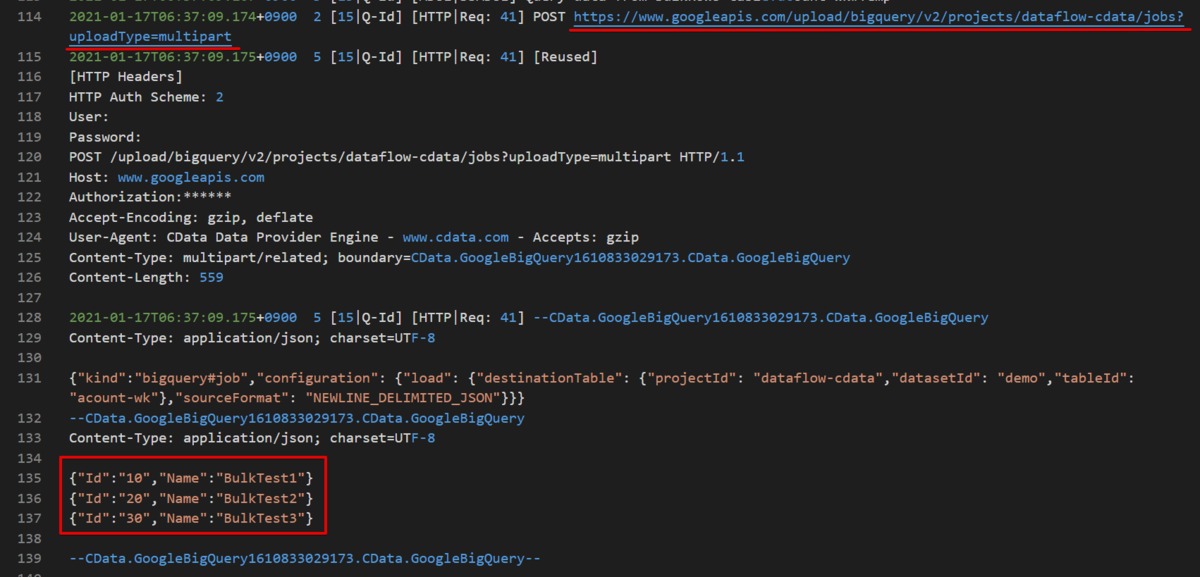
こちらも同じように接続文字列に "InsertStrategy=batch" を設定してから SQL を実行してみます。
insert into [acount-wk] (Id,Name) values (10,BulkTest1), (20,BulkTest2), (30,BulkTest3)
ログを確認すると、API アップロードを呼び出しているのが確認できます。データ件数が少ないのでわかりずらいですが、1リクエストで全てのレコードを送信することができます。
API uploads | BigQuery | Google Cloud
CData BigQuery JDBC Driver でパフォーマンス比較
以下のような10カラムのデータを使って、100件、500件、5000件、10000件でそれぞれ計測してみました。
(9999,insertTest,xxxxxxxxxxxxxxxxxxx,xxxxxxxxxxxxxxxxxxx,xxxxxxxxxxxxxxxxxxx,xxxxxxxxxxxxxxxxxxx,xxxxxxxxxxxxxxxxxxx,xxxxxxxxxxxxxxxxxxx,xxxxxxxxxxxxxxxxxxx,xxxxxxxxxxxxxxxxxxx),
それぞれ実行した結果になります。
| Insert 方法 | 100件 処理時間(s) |
500件 処理時間(s) |
5000件 処理時間(s) |
10000件 処理時間(s) |
|---|---|---|---|---|
| ストリーミング | 0.491 | 1.162 | 8.928 | 13.788 |
| DML | 1.617 | 2.482 | 3.312 | 3.852 |
| バルク | 1.447 | 1.405 | 1.751 | 2.801 |
結果として、やはり 1リクエスト 500件までを推奨しているストリーミングインサートは、100件、500件までは最も高速に処理を行ってますね。それ以降は複数回のリクエストが行われるので処理時間が増えてしまいました。
バルクインサートについては、かなり安定したパフォーマンスを出せてました。500件以上をインサートする場合は、バルクインサートが良さそうです。
DML は想定していた処理時間よりもパフォーマンスが良かったですね。ただ、1レコードあたりのデータサイズが今回よりも大きかったら、もっとはっきりしていたかもしれません。
おわりに
いかがでしたでしょうか。BigQuery へのデータローディングにはいくつかの方法で行えることがわかったと思います。利用されるユースケースやデータ量で使い分けることが良さそうですね。
今回ご紹介した CData BigQuery JDBC Driver は 以下のリンクより 30 日間のトライアル利用が可能です。
もちろん、JDBC 以外にも ODBC やPython、Excel などでもトライアル利用が可能ですので、是非お試しください。