はじめに
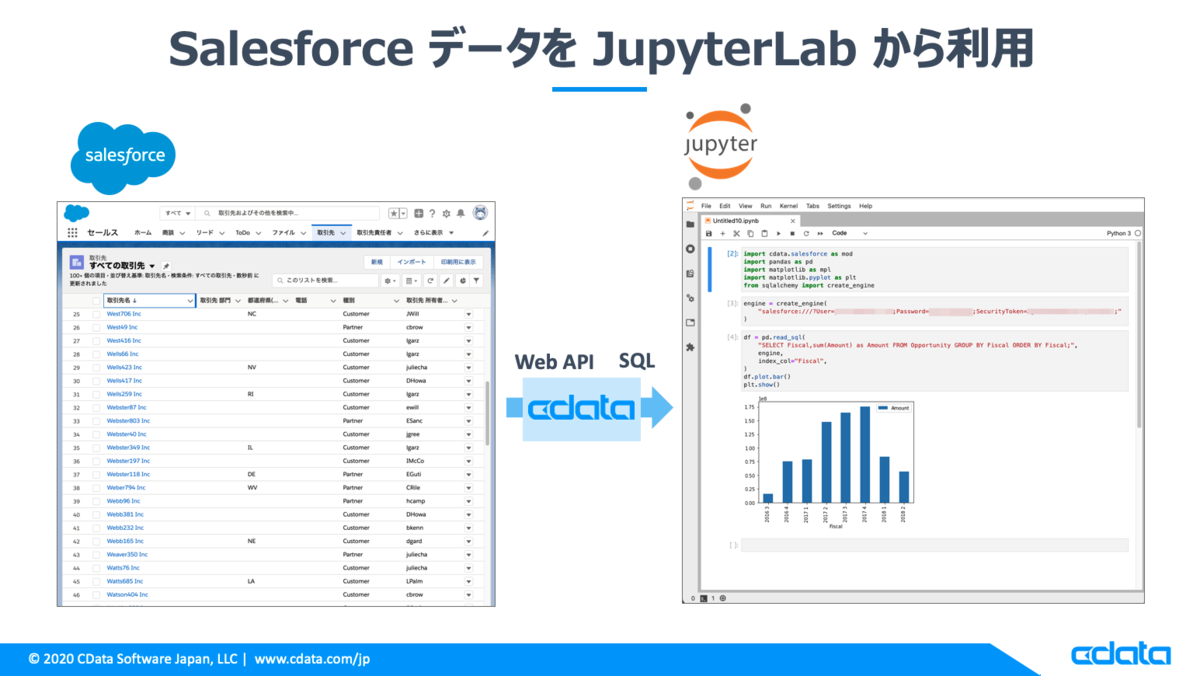
CData技術ディレクター桑島です。この記事では、Pythonでのデータ分析ツールとして人気があるJupyterLabで、SalesforceのデータをSQLで取得してpandas.DataFrameとして扱う方法をご紹介します。
前提
この記事では、Python、pip、および、JupyterLabのインストール手順を含みません。本手順で使用するCData Salesforce Python Connectorの対応Pythonバージョンは以下の通りです。
以下のPythonライブラリのインストールが必要です。
pipコマンドでインストールしてください。
$ pip install jupyterlab $ pip install pandas $ pip install matplotlib $ pip install sqlalchemy
CData Salesforce Python Connector のインストール
本手順では、Salesforceデータ連携用に、SQLでアクセス可能なDB-APIモジュールであるCData Salesforce Python Connector を利用します。CData Salesforce Python Connector は、以下サイトよりダウンロードすることができます。
※本記事執筆時点(2020/12)ではベータ版でのご提供です。
ダウンロードしたファイルを解凍すると「プラットフォーム(mac / unix / win)> Pythonバージョン > 32/64bit」のフォルダ内に.whlファイルが格納されています。
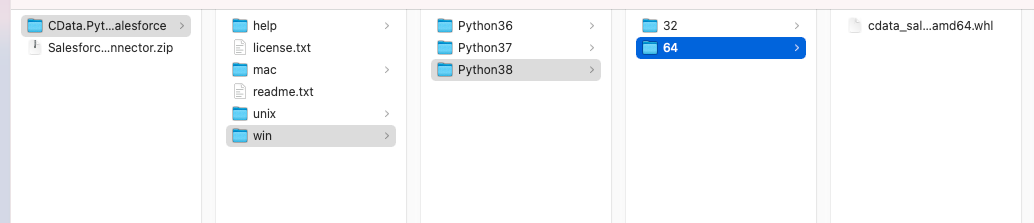
実行環境にあった.whlファイルを選択して、pipコマンドでモジュールをインストールしてください。以下は、mac環境での実行例です。
$ cd ./CData.Python.Salesforce/mac/Python38 $ pip install cdata_salesforce_connector-20.0.XXXX-cp38-cp38-macosx_10_9_x86_64.whl Processing ./cdata_salesforce_connector-20.0.XXXX-cp38-cp38-macosx_10_9_x86_64.whl Installing collected packages: cdata-salesforce-connector Successfully installed cdata-salesforce-connector-20.0.XXXX
インストールしたらpip listコマンドで登録されているか確認します。
$ pip list : cdata-salesforce-connector 20.0.XXXX :
モジュールのインストールについて詳細な情報は以下の製品マニュアルをご覧ください。
JupyterLabからの利用
以下のコマンドでJupyterLabを起動します。
$ jupyter lab
ブラウザが起動してLauncher画面が開きます。今回は、対話式にコマンドを入力して確認していきますので、NotebookないのPython3を選択します。
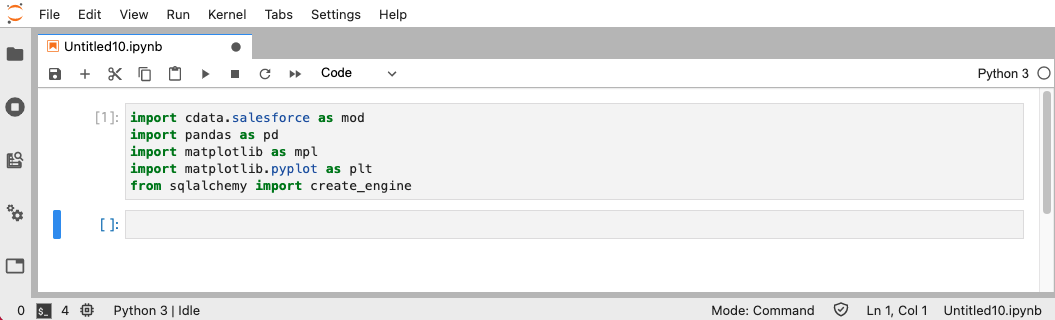
Codeラインに以下コマンドを入力して必要ライブラリをインポートします。
import cdata.salesforce as mod import pandas as pd import matplotlib as mpl import matplotlib.pyplot as plt from sqlalchemy import create_engine
次に、SQLAlchemyのcreate_engineでDB(今回はSalesforce)への接続を定義します。Salesforceへの接続に必要なパラメータは、User, Password, SecurityTokenの3つです。
engine = create_engine(
"salesforce:///?User=XXXXX;Password=XXXXX;SecurityToken=XXXXX;"
)
SalesforceでのSecurityTokenの取得方法はこちらの記事をご参照ください。
なお、Salesforceへの接続にはOAuthでの接続もサポートしています。詳細はこちらの製品マニュアルをご参照ください。
まずは、SalesforceのOpportunity(商談)オブジェクトのデータを参照して出力してみます。
df = pd.read_sql("SELECT Id, AccountId, Name, StageName, Amount, Probability , ExpectedRevenue, CloseDate, Type, LeadSource, IsClosed , IsWon, Fiscal FROM Opportunity LIMIT 10;", engine) print(df)
Opportunityのテーブル項目はこちらの製品マニュアルからご覧いただけます。
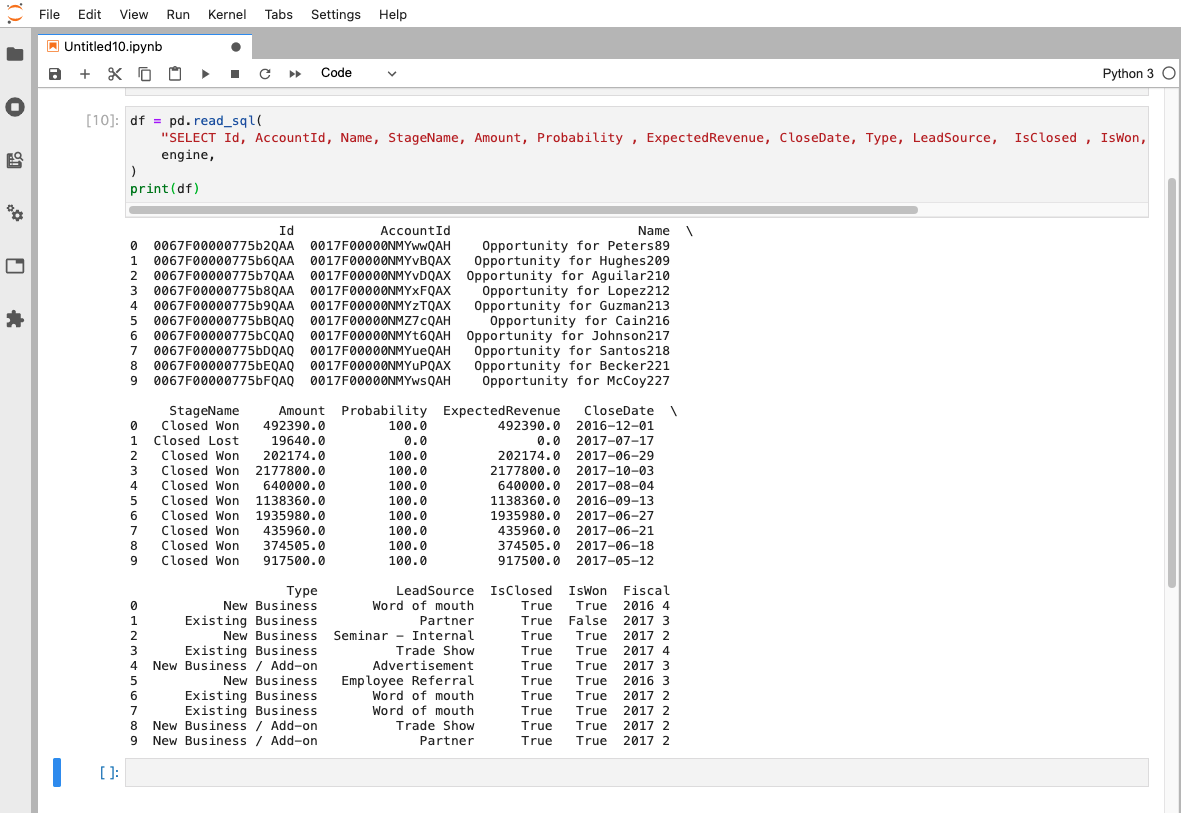
10件分の商談情報が取得できたことを確認できました。
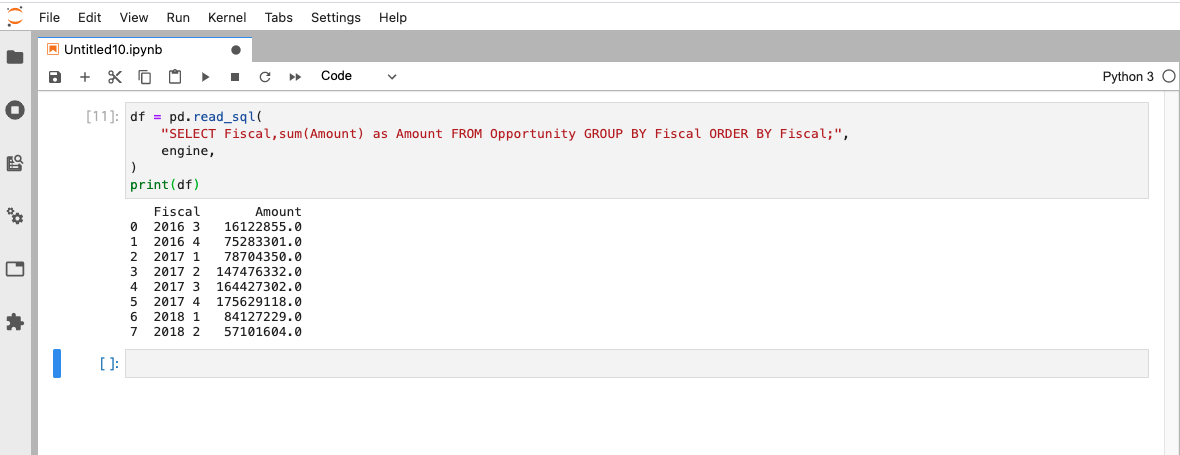
それでは次にこの商談情報をもとにFiscal(四半期)毎のAmmount(金額)集計をみていきます。Dataframeをgroupbyする方法もありますが、今回はSQLで集計してみたいと思います。
df = pd.read_sql("SELECT Fiscal,sum(Amount) as Amount FROM Opportunity GROUP BY Fiscal ORDER BY Fiscal;", engine) print(df)
Salesforceのクエリー言語であるSOQLではなくSQLであることに注意です。SQL構文規約は以下の製品ヘルプをご参照ください。
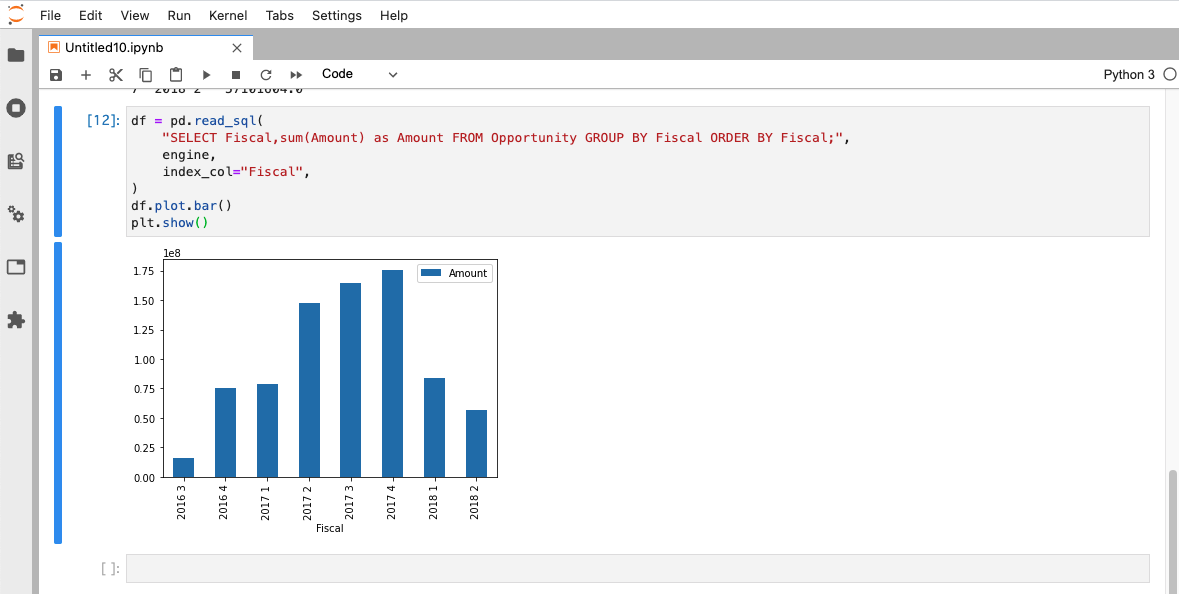
最後に、年度毎の金額をmatplotlibを使用して棒グラフで可視化してみましょう。
df = pd.read_sql(
"SELECT Fiscal,sum(Amount) as Amount FROM Opportunity GROUP BY Fiscal ORDER BY Fiscal;",
engine,
index_col="Fiscal",
)
df.plot.bar()
plt.show()
まとめ
この記事では、Pythonでのデータ分析ツールとして人気があるJupyterLabで、SalesforceのデータをSQLで取得してpandas.DataFrameとして扱う方法をご紹介しました。DB-APIとしてアクセスできるCData Salesforce Python Connectorを利用することでSQLite,MySQL, PostgreSQLのようなRDBMSのデータを扱うのと同じ方法でSalesforceのデータにアクセスできました。CData Softwareでは、Salesforceの他にも220を超えるSaaS、NoSQL、ビッグデータ連携用のDB-APIモジュールを提供しています。
https://www.cdata.com/jp/python/
現在(2020/12時点)では、ベータ版での提供となり、製品へのフィードバックを絶賛受付しております。JupyterLabを利用してPythonでSaaSやNoSQLのデータを活用されている方は是非お試しくださいませ。本製品についてご不明な点などがございましたらこちらのCData Software Japanサポート窓口までお問い合わせください。