
こんにちは。CData Software Japan リードエンジニアの杉本です。
AWS で提供されているDWHサービスである「Amazon Redshift」のサーバーレス版、「Amazon Redshift Serverless」が去年の年末に発表されましたね。
今までのAmazon Redshift であれば、ある程度コンピューティングリソースを予測しながら、予めクラスターのセットアップや管理を行う必要がありましたが、このAmazon Redshift Serverlessの登場により、より柔軟なAWS上でのDWH運用、活用が可能になりました。
私もAmazon Redshiftはたびたび検証で活用していますが、やっぱりクラスターのセットアップはちょっと面倒なものです。また、クラスターの起動・停止を忘れて課金がそのままされてしまうのも怖いところですよね。それがAmazon Redshift Serverless でとても手軽に利用・管理できるようになりました。
さて、今回の記事ではこのAmazon Redshift Serverless に対して、CDataが提供するデータパイプラインツール「CData Sync」を使い、各種SaaSのデータをレプリケーションしてみたいと思います。
Amazon Redshift Serverless へ接続するための注意点・課題
Amazon Redshift Serverlessは通常のAmazon Redshiftと同様にJDBC Driverなどから接続するためのエンドポイントが公開されています。
ただ、ここで注意しなければいけないのですが、Amazon Redshift Serverless は現在プレビュー段階のためか、パブリックエンドポイントが公開されておらず、VPC内から接続を行う必要があります。

AWS 以外のクラウドホスティングのサービスの場合、ここが接続の際のボトルネックになりますが、CData Syncの場合、AWS EC2に環境をセットアップして利用できるので、こういった制約に対して柔軟な対応を図ることが可能です。

そこで今回はAWS EC2で構成したAmazon Linux 環境にCData Sync Cross-Platform版をセットアップして、接続してみます。
環境の構築方法は以下の記事を参考にしてみてください。
手順
Amazon Redshift Serverless 環境の構築
さて、まずはAmazon Redshift Serverless 環境を構築してみましょう。
Amazon Redshift の画面に移動し「Amazon Redshift サーバーレスの開始方法(プレビュー)」から構築していきます。
最初にサーバーレスクレジットを指定しますが、今回は検証用途なので「Choose starter base configuration」を指定しています。これで使用されるリソースが節約できるようです。
また、設定は特に変更せず、「Use default settings」を利用しました。

これで「サーバーレスエンドポイントを作成」をクリックすると数分で環境が構成されます。
以下のようにServerless dashboardの画面に遷移したら、試しにサンプルデータを使ってクエリしてみましょう。
「Query data」をクリックすることで、「Redshift Query Editor V2」に移動します。
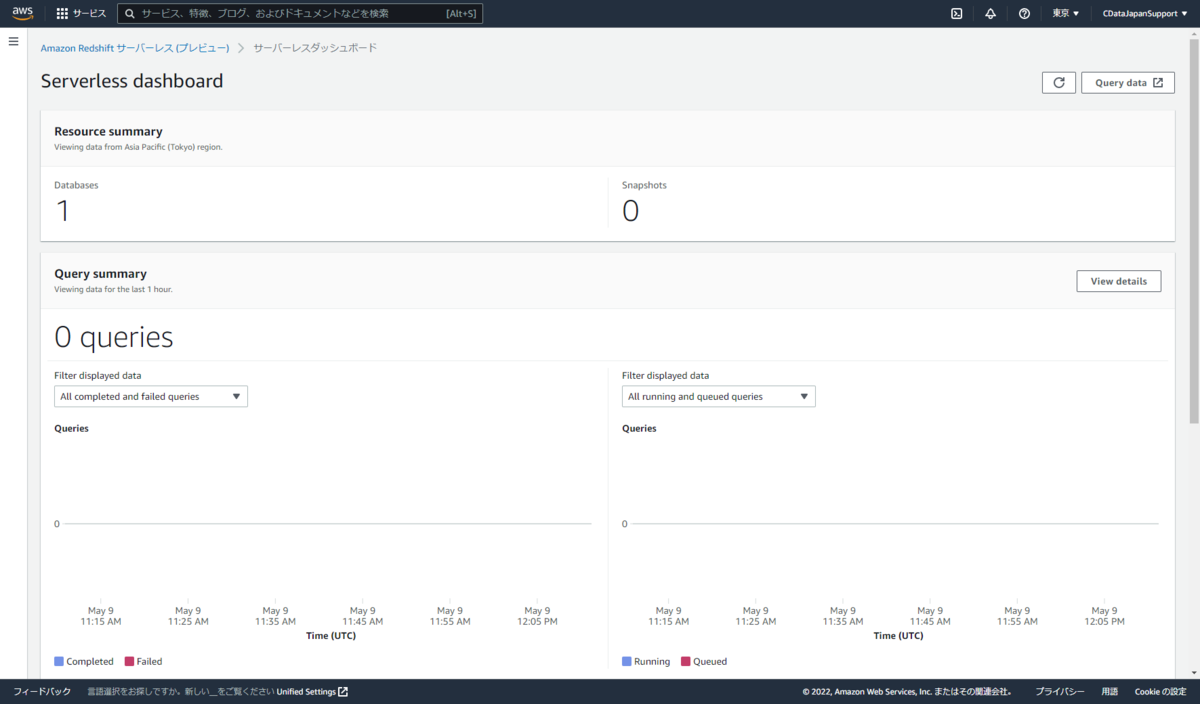
「Serverless」データベースが構築した環境です。それ以外のclusterと表示されているのは元々Amazon Redshiftで構成していたクラスターですね。
サンプルデータを登録するために「Serverless」→「sample_data_dev」から「tickit」を選択してみます。

展開が完了すると、以下のように各種サンプルテーブルが利用できるようになります。あとはクエリを行えば、そのままServerlessリソースを活用しながら、データの取得・分析ができます。
Query Editor V2ではNotebookやChartsの機能もついているので、ここだけで分析や分析結果の共有がスムーズに実現できそうで良いですね。

CData Sync で Amazon Redshift Serverless に接続を行う
それでは CData Sync で Amazon Redshift Serverless に接続を行ってデータをレプリケーションしてみましょう。とは言っても、基本的にAmazon Redshift接続を利用する場合とアプローチは変わりません。
なお、今回は予めAmazon Redshift Serverless 側の接続ユーザー・Passwordを変更しておきました。
レプリケーションするデータは CRM SaaS の Salesforce を使っていますが、CData Sync が提供している任意のデータソースで構いません。
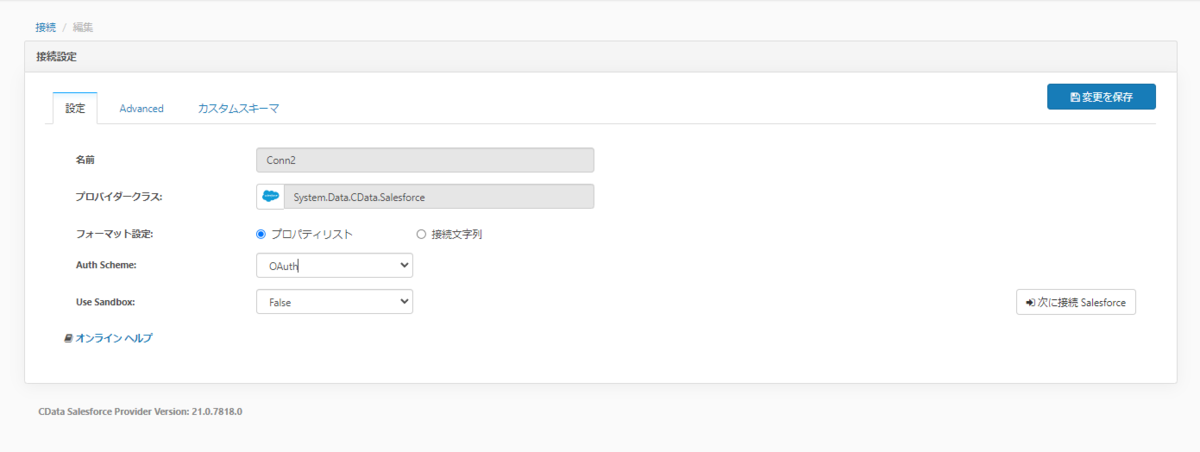
Amazon Redshift Serverless への接続には元々CData Sync で提供されている Amazon Redshift コネクタがそのまま利用可能です。
「接続」画面に移動し「同期先」の一覧から「Amazon Redshift」を選択します。

以下のように接続情報を入力し、「接続テスト」が成功すればOKです。変更を保存しておきます。
| プロパティ名 | 値 | 備考 |
|---|---|---|
| Auth Scheme | Basic | |
| Server | 例)12345678.ap-northeast-1.redshift-serverless.amazonaws.com | Serverless configurationの画面のendpointで確認できます。 |
| Port | 5439 | |
| Database | 例)dev | 接続先となるDatabase Nameを選択します。 |
| User | 例)admin | 予め設定しておいた管理ユーザーのIDを入力します。 |
| Password | 例)YOUR_PASSWORD | 予め設定しておいた管理ユーザーのPasswordを入力します。 |

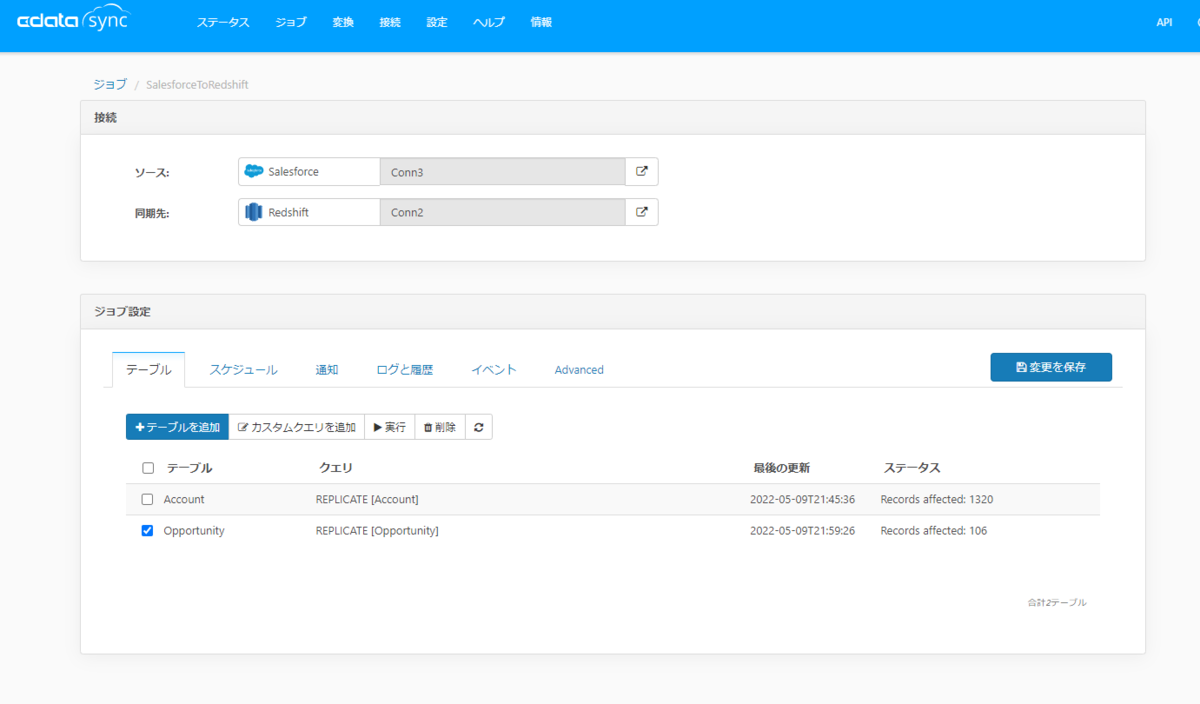
あとは元々構成しておいたSalesforce からデータを取り込むジョブとして作成します。

今回は以下のようにSalesforce の「Account」と「Oppotunity」のデータをレプリケーションしてみました。
無事成功すると、ステータスにレプリケーションされたレコード数が表示されます。
Amazon Redshift Serverless の Query Editor に移動してみると、以下のように各種テーブルが作成されたことが確認できます。

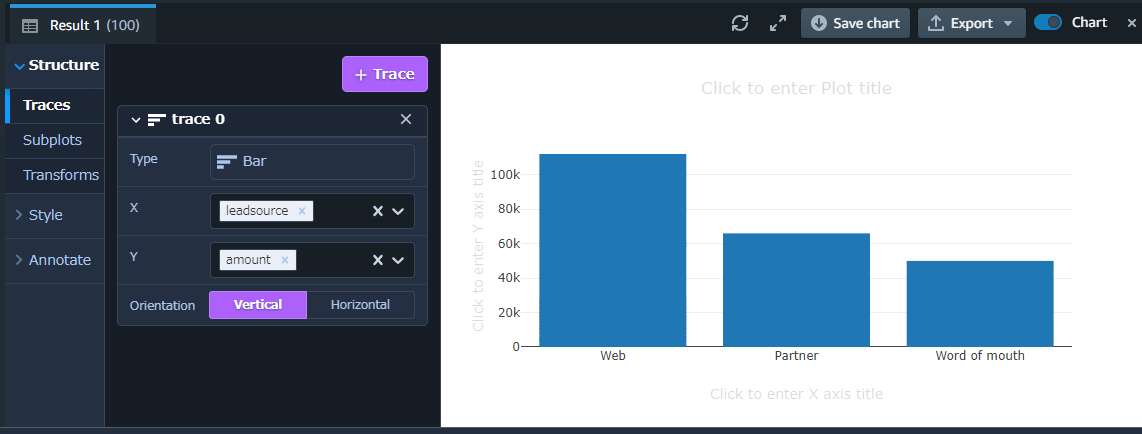
せっかくなのでQuery Editor のグラフ機能を使ってOppotunity の分析もしてみました。このままスムーズにSalesforce のデータを可視化、分析できるのは良いですね。
おわりに
このように CData Sync を使うことで、手軽にAmazon Redshift Serverless にデータを取り込むことができます。
環境構築もAmazon VPC内で完結できるので、セキュアに利用できるのもポイントです。
CData Sync では Salesfroce 以外にも約400種類の様々なデータソースをサポートしているので、是非お好みのデータソースでデータパイプライン構築を試してみてください。
ご不明な点があれば、お気軽にテクニカルサポートフォームまでお問い合わせください。