こんにちは。CData Software Japan リードエンジニアの杉本です。
今回は CDataSync の連携先の一つとしてよくご相談をいただく、Amaozn S3 Destination の使い方を解説したいと思います。
Amazon S3 Destination とは?
任意の Amazon S3 Bucket に Salesforce や Kintone など、多様なデータソースから取得したデータをCSVとして吐き出す機能です。
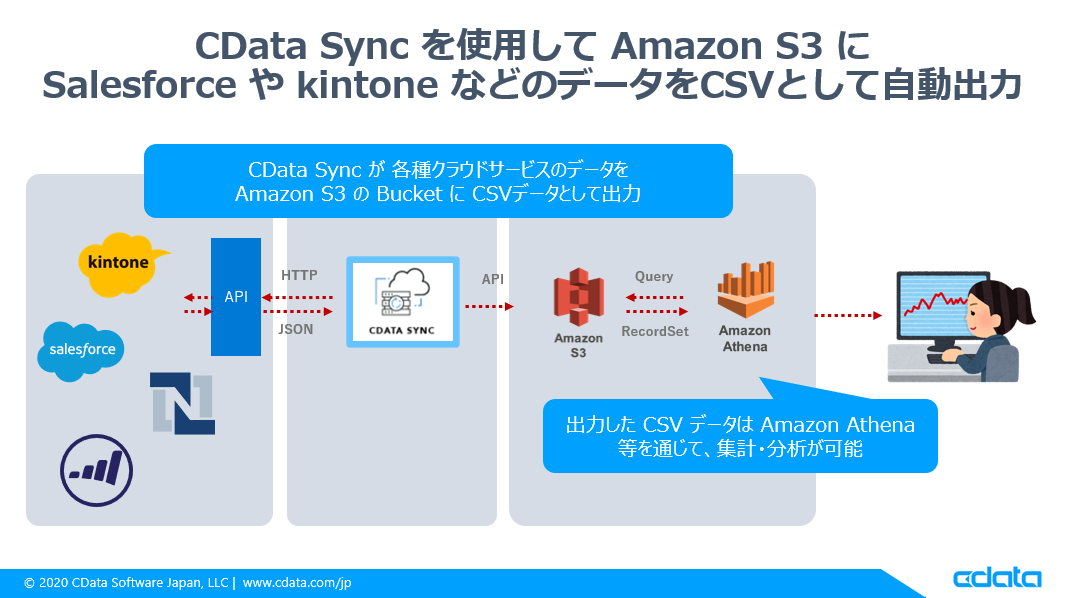
出力先のAmazon S3をデータレイクとして活用し、Amazon Athena などと組み合わせて、大量のデータを集計・分析することが可能になります。
利用手順
それでは実際に使い方を解説していきましょう。
CData Sync のセットアップ
CData Sync を以下のURLからダウンロードして任意の環境にセットアップしておきます。
今回は手順を割愛しますが、Windows・Linux・Amazon AMIなど好みの環境でセットアップできます。
https://www.cdata.com/jp/sync/

セットアップ後、情報タブからトライアルライセンスを有効化しておいてください。

IAM ユーザーの準備
CDataSync から Amazon S3 への接続にはIAMユーザーのAccessKeyとSecretKeyが必要になります。
手順は割愛しますが、Amazon S3 へのアクセス権を付与したユーザーを作成しておいてください。

ちなみに Amazon S3 の接続はIAMユーザーベースの接続と、IAM ロールを用いた接続の2種類がサポートされています。

もしIAM ロールによる接続を行う場合は、対象のロールにAssumeRoleできる権限を持つIAMユーザーおよびAmazon S3へのアクセスポリシーを持つIAMロールを準備してください。
今回はIAMユーザーによる接続で構成します。
Amazon S3 Bucket の準備
続いてデータの保存先となる Amazon S3 の Bucket も構成しておきます。今回は 「s3://cdatajwrk/ReplicateFolder」というフォルダを作成しました。
接続構成
準備が整ったので、CData Syncの接続構成を行っていきましょう。
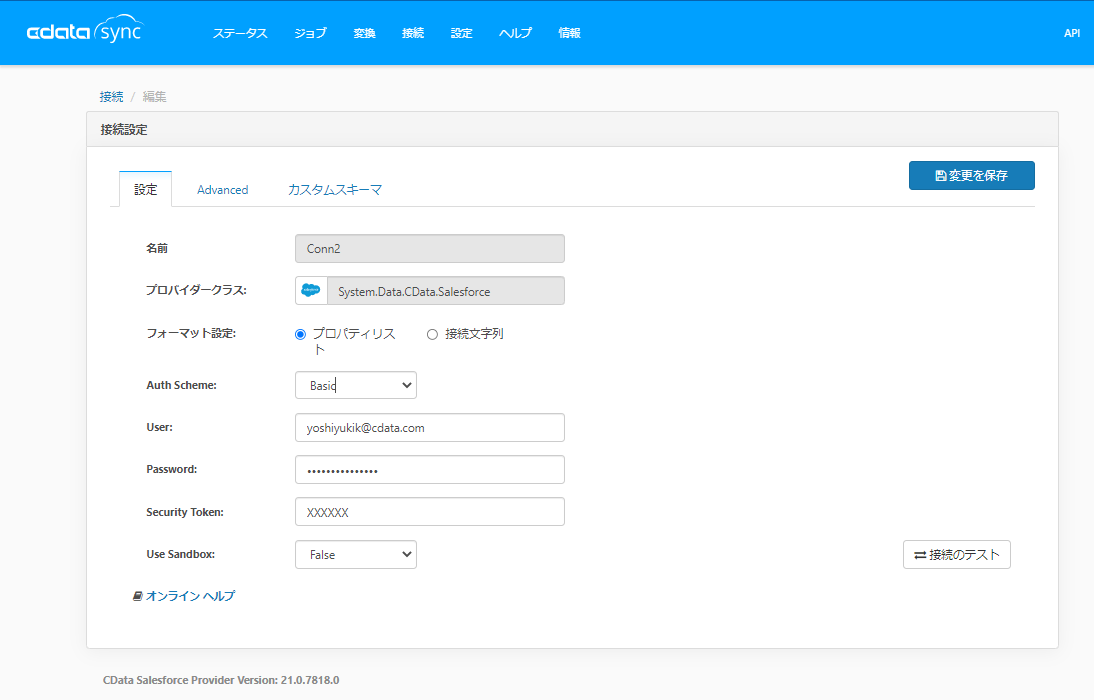
まず、Amazon S3 への接続構成を行います。
「接続」→「同期先」から「Amazon S3」を選択します。

以下のように接続情報を入力して、接続テストを行い、問題が無ければ「変更を保存」をクリックします。
| プロパティ名 | 値 | 備考 |
|---|---|---|
| AWS Access Key | 例)AKIATGQKTWNACHQAMZF6 | 作成したIAMユーザーのアクセスキーを指定 |
| AWS Secret Key | 例)l33Ygzol2YCUJuZL/1p32OkfSGe7UTNUczA/wMRS | 作成したIAMユーザーのシークレットキーを指定 |
| AWS Region | 例)TOKYO | |
| Bucket | 例)s3://cdatajwrk/ReplicateFolder | 対象のS3バケットを指定 |
| Auth Scheme | AwsRootKeys |

Amazon S3 Destination の設定が完了したら、データの取得先となる設定も追加しましょう。
今回はSalesforceを対象にしてみました。
ジョブの作成と実行
接続構成が終わったので、さっそくジョブを作成してみましょう。
「ジョブ」→「ジョブを追加」をクリックし
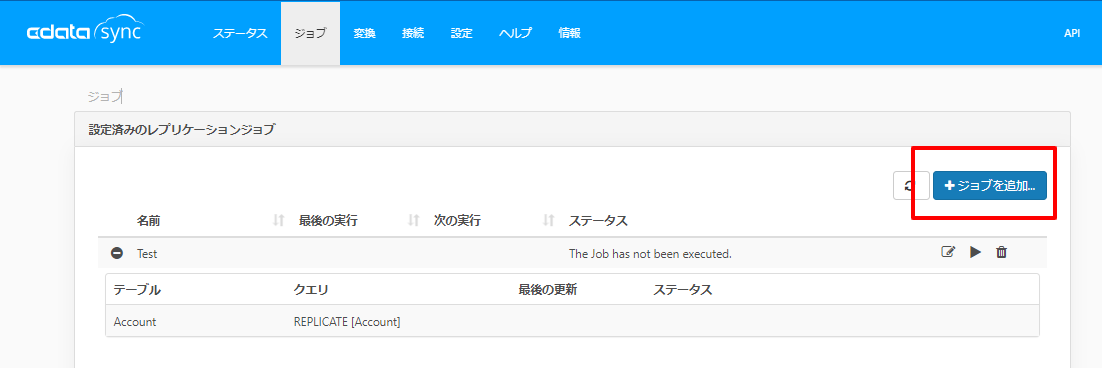
ソースで「Salesforce」、同期先として「Amazon S3 Destination」をそれぞれ選択します。
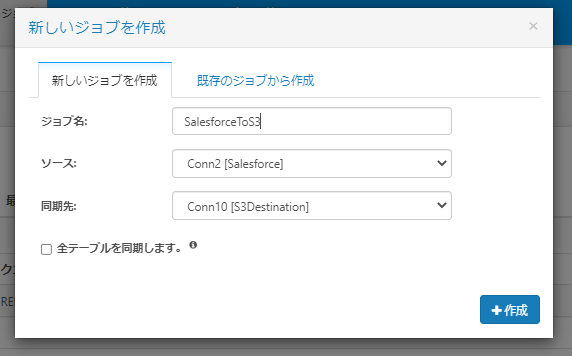
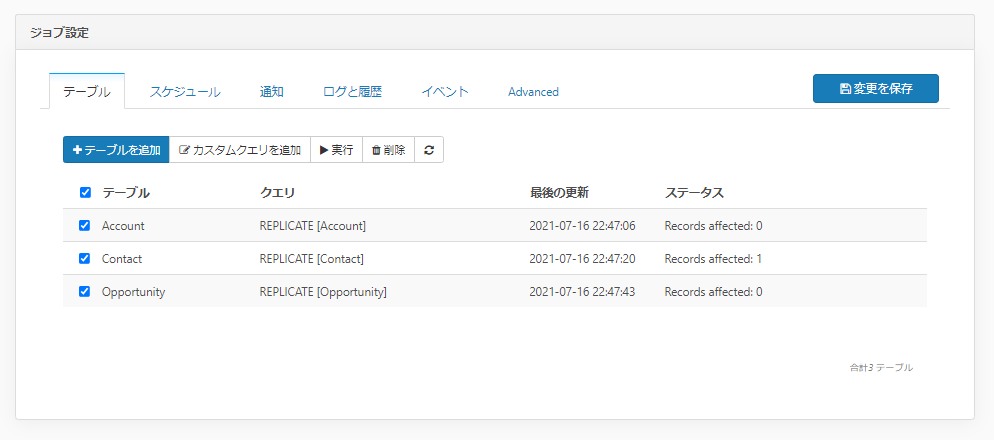
ジョブを作成したら同期対象となるSalesforceのデータ、テーブルを追加します。

今回は以下の3種類のテーブルを追加してみました。
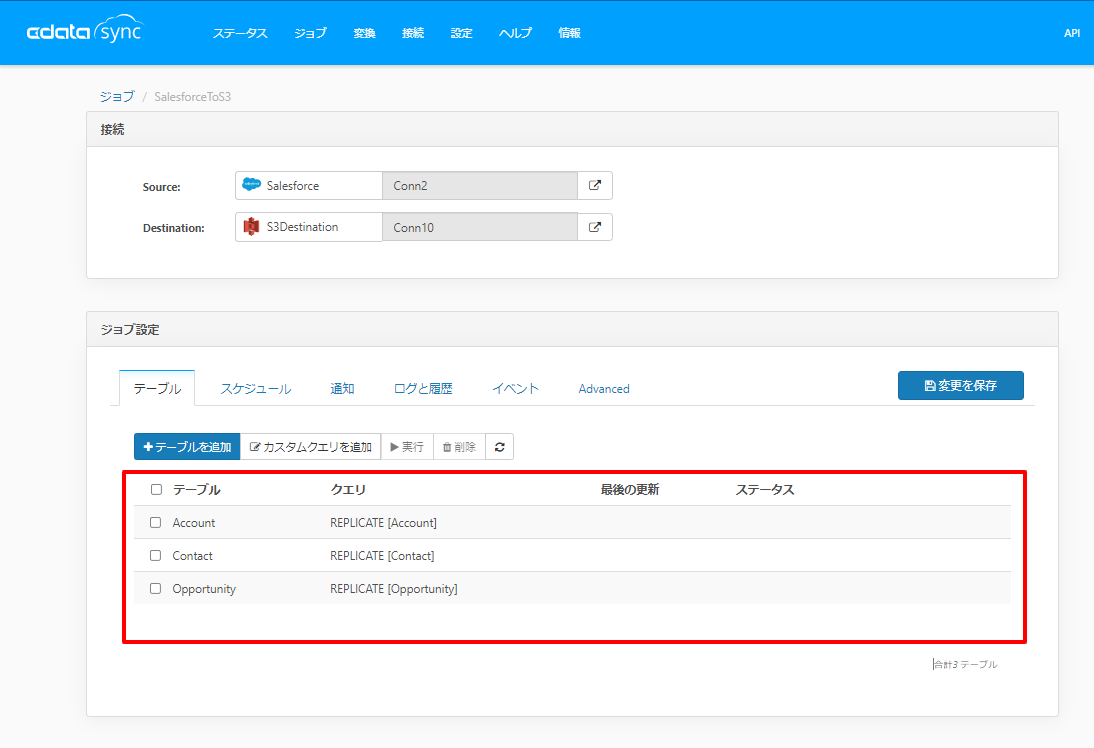
あとは任意のスケジュールを指定して実行するだけです。ただ、今回はとりあえず試したいので手動実行してみます。
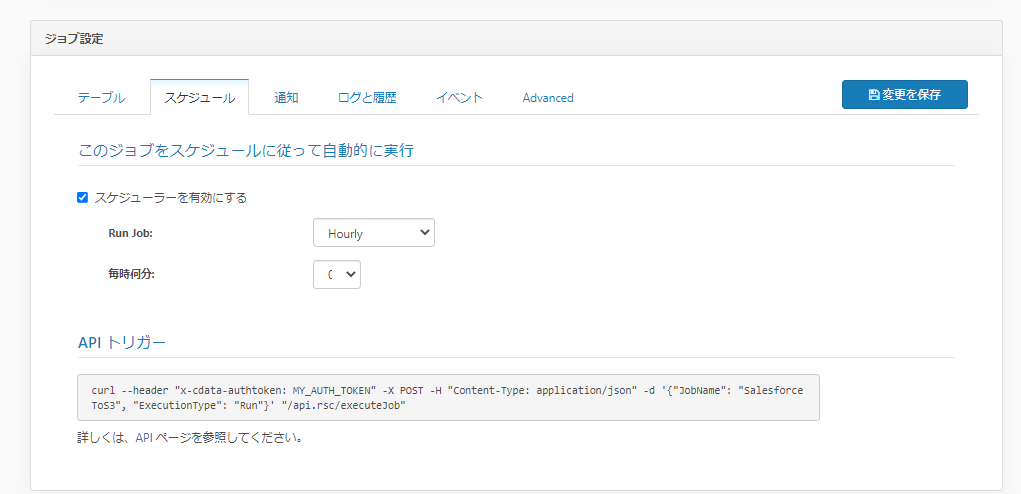
対象のテーブルを選択して「実行」ボタンをクリックすると、以下のようにデータのレプリケーションが実施され、ステータスに結果が表示されます。

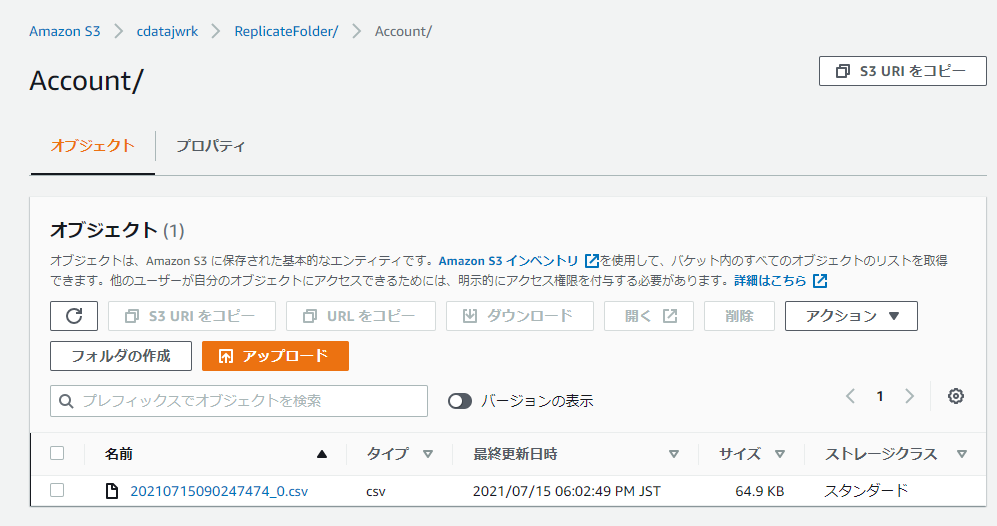
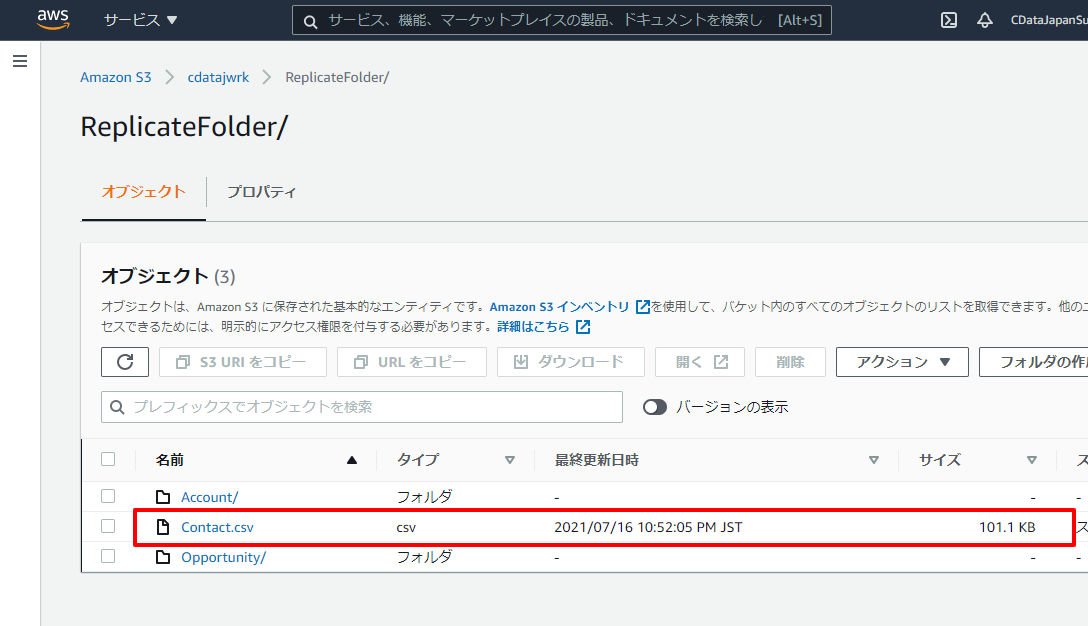
Amazon S3の対象にした Bucket にアクセスしてみると、以下のように同期対象としたテーブルのフォルダがそれぞれ作成され

中にCSVファイルが生成されていました!
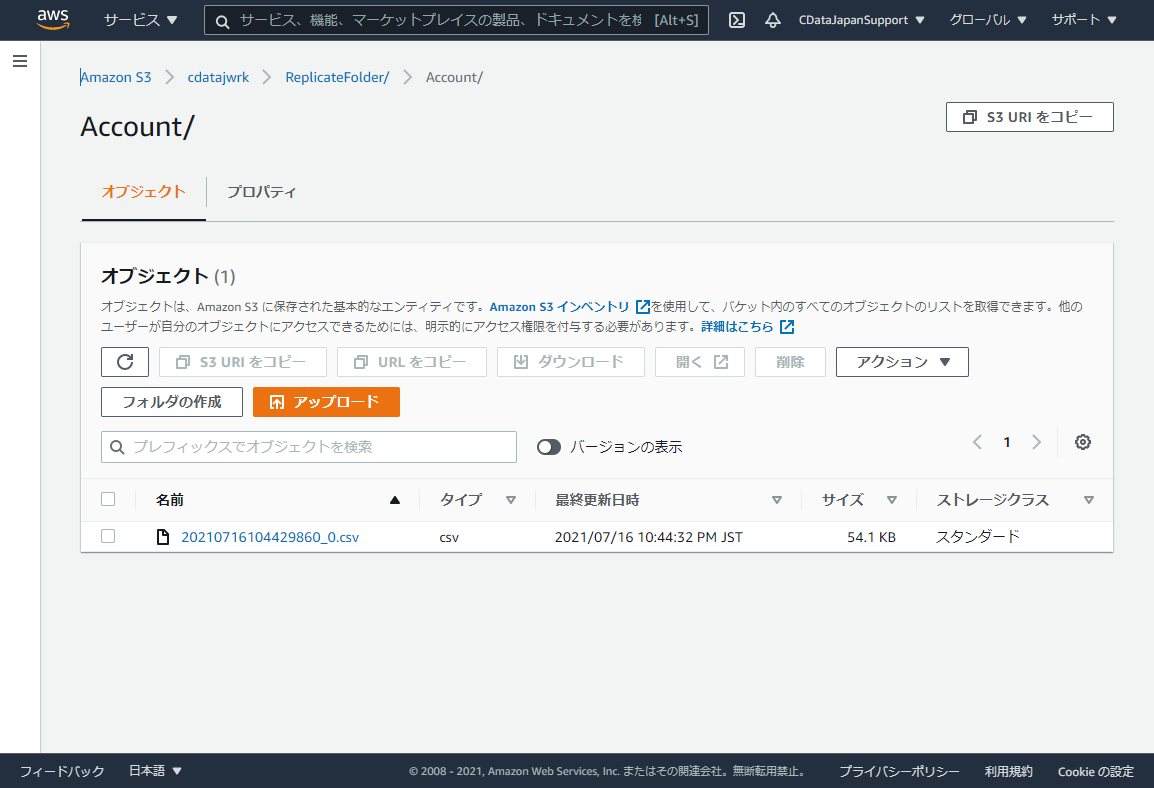
CSVファイルをダウンロードしてみると、ちゃんとSalesforceのデータが出力されていることが確認できます。

データ登録の挙動について
最後にデータ登録の挙動についてお伝えしておきます。
デフォルトでは、データが更新されたり登録されたら、新しくCSVファイルが生成されます。
例えば、以下のようにSalesforceの「Contact」データを更新してみると
ステータスには以下のように表示されます。更新した「Contact」のデータだけが、同期結果1件となりました。
Amazon S3を覗いてみると、以下のようにCSVファイルが追加されています。
このようにデフォルトでは登録・更新レコードがどんどん追加されていく仕様になっています。

ちなみにこの挙動はAmazon S3 Destination接続設定にある「Insert Mode」の「FilePerBatch」の挙動です。
例えばこの設定を「SingleFile」にして実行してみると
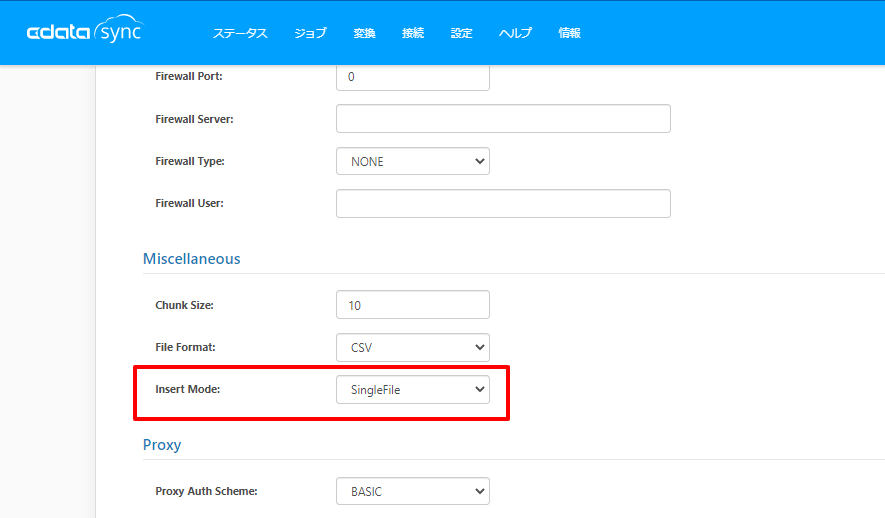
先程のようなフォルダは作成されず、単一のCSVファイルが生成されます。
データの更新や作成・削除が発生しても常にこのCSVが更新される、という仕様になります。
おわりに
というわけでざっと解説してきましたが、この他にも細かなチューニングや機能が色々と備わっています。
またBlogでも解説したいと思いますが、もし触っていてわからない点、気になる点があれば、テクニカルサポートまでお気軽にどうぞ!