
こんにちは。CData Software Japan リードエンジニアの杉本です。
今回はCData Sync の新機能として、ジョブの並列処理がサポートされたので、お伝えしたいと思います!
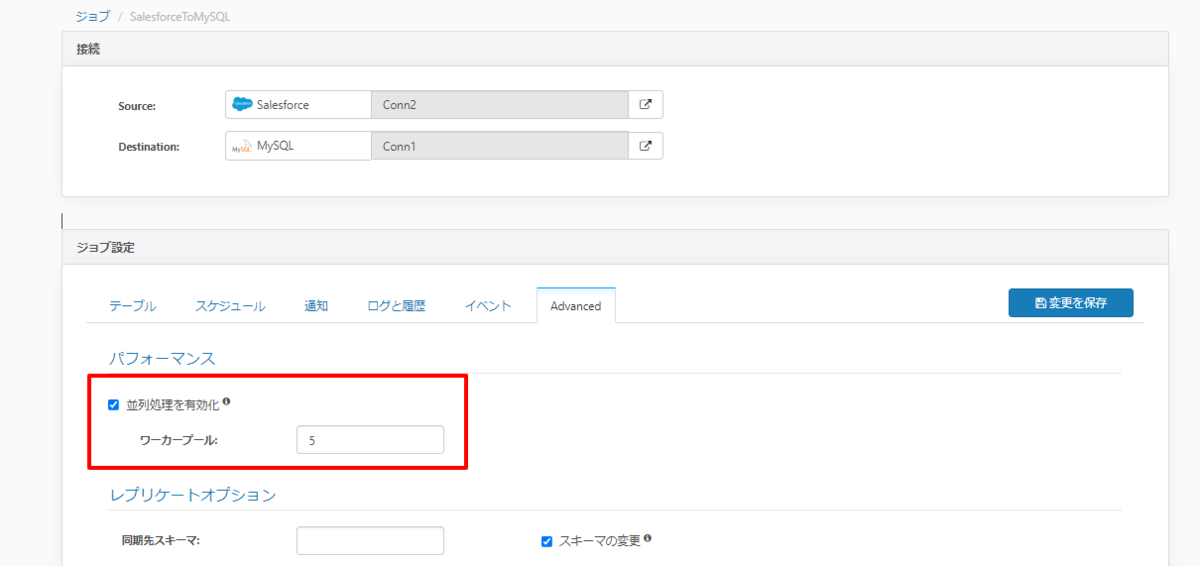
概要
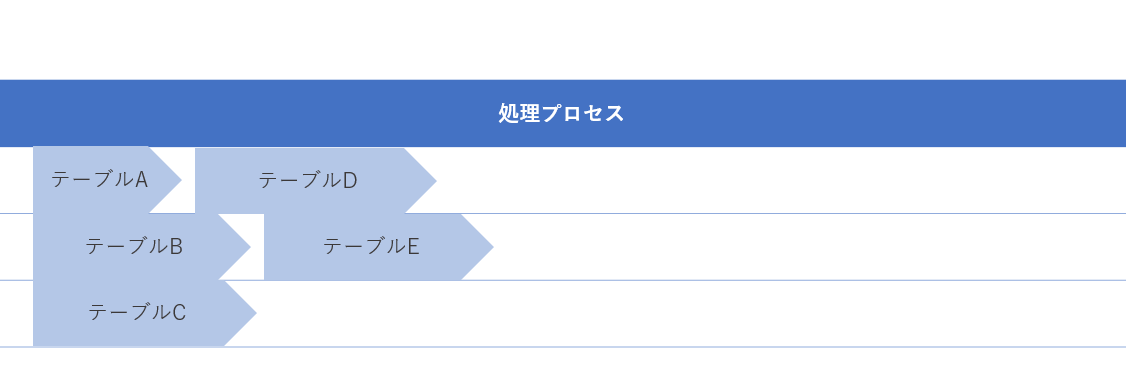
CData Sync では一つのジョブの中で複数のテーブルのレプリケーションを定義することができるようになっています。
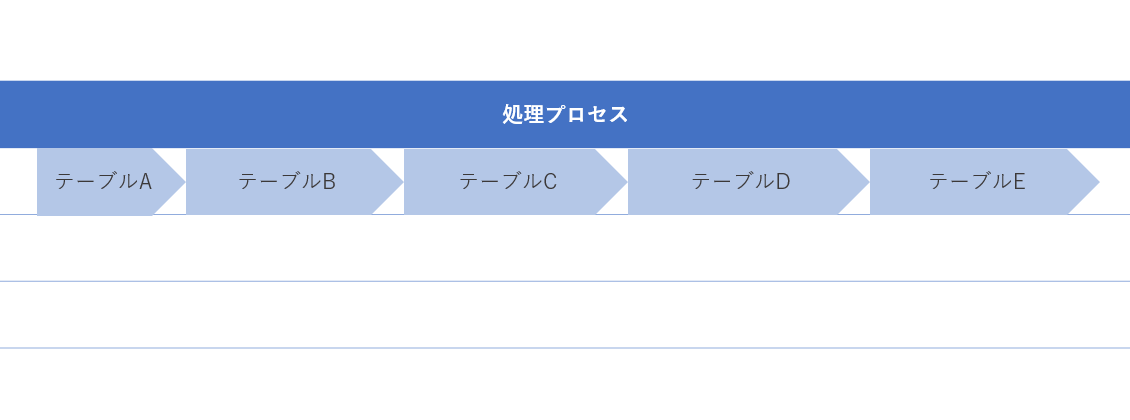
従来はこのジョブの中での処理はシリアルに一つ一つのテーブルがレプリケーションされるようになっており、1つ目のテーブルの処理が終わらない限り、次のテーブルの処理は進みませんでした。
最新バージョンではジョブの設定において並列処理を有効化し、任意のワーカープール数を指定することで、パラレルにテーブルのレプリケーションが実行できるようになっています。
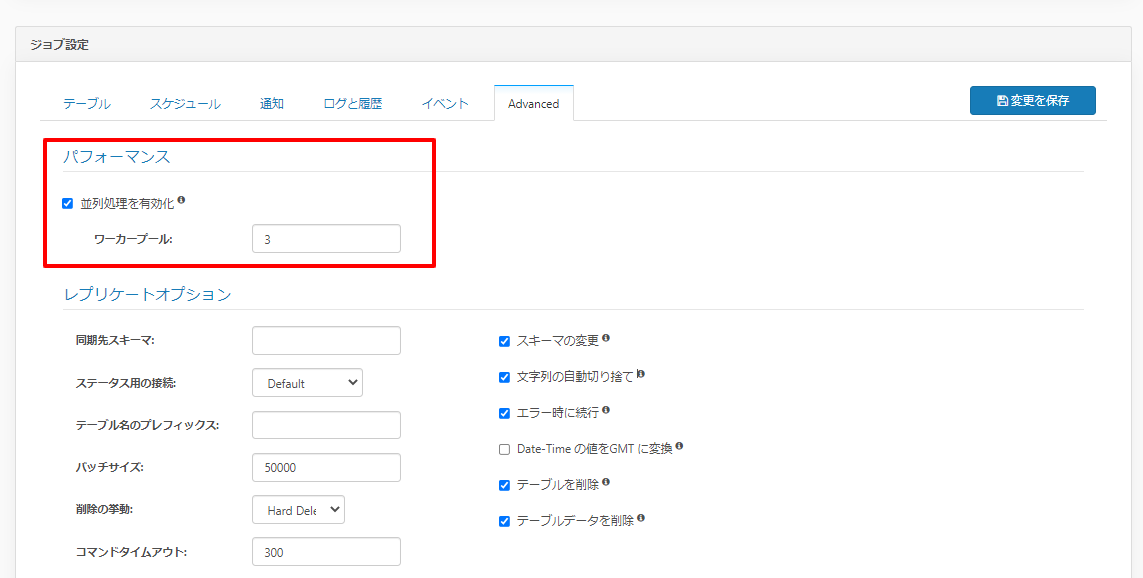
これにより、一つ一つのテーブルの処理完了を待たずに、多くのレプリケーションを並列して処理できるようになりました。
処理パフォーマンスを比較してみる
せっかくなので、シリアルとパラレルの処理でどのくらいパフォーマンスに変化がでるのか、検証してみました。
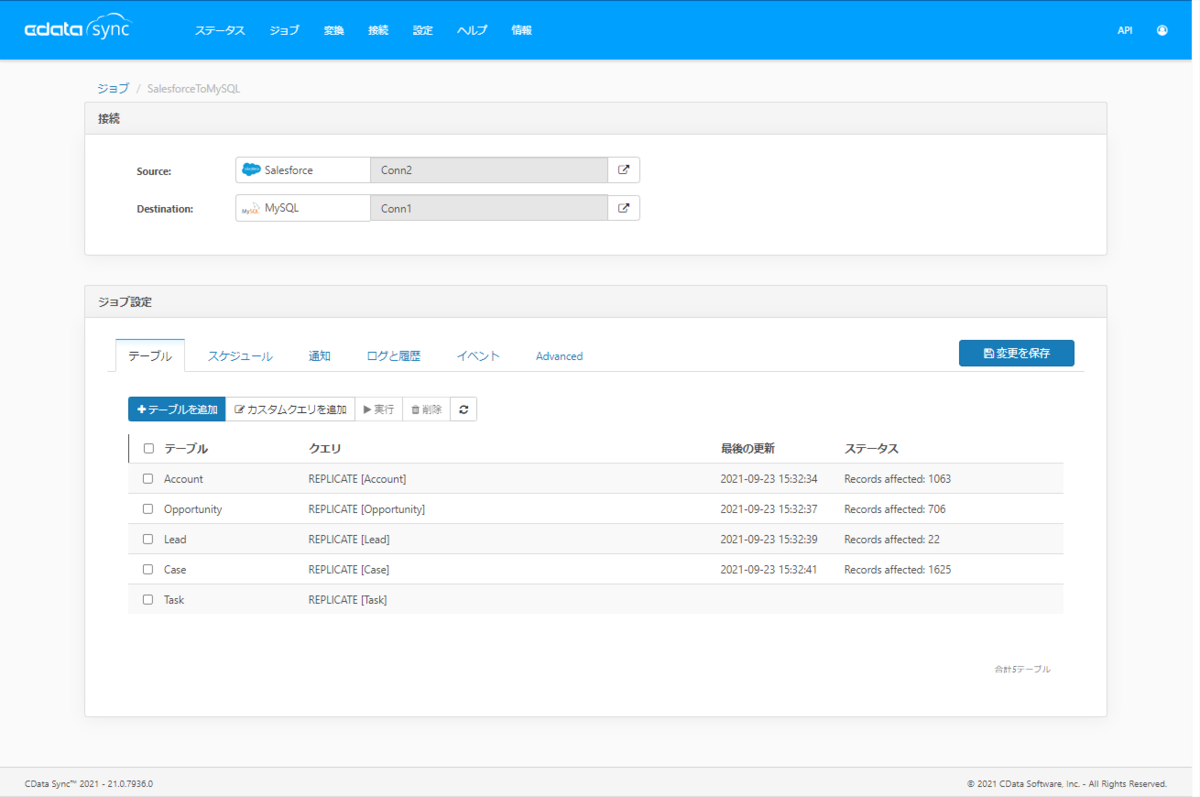
今回はSalesforceから5種類のテーブルを対象に、MySQLへレプリケーションしてみます。
レプリケーションオプションでテーブルは一度削除するようにしているので、差分は意識せず、毎回同じレプリケーションが実行されます。
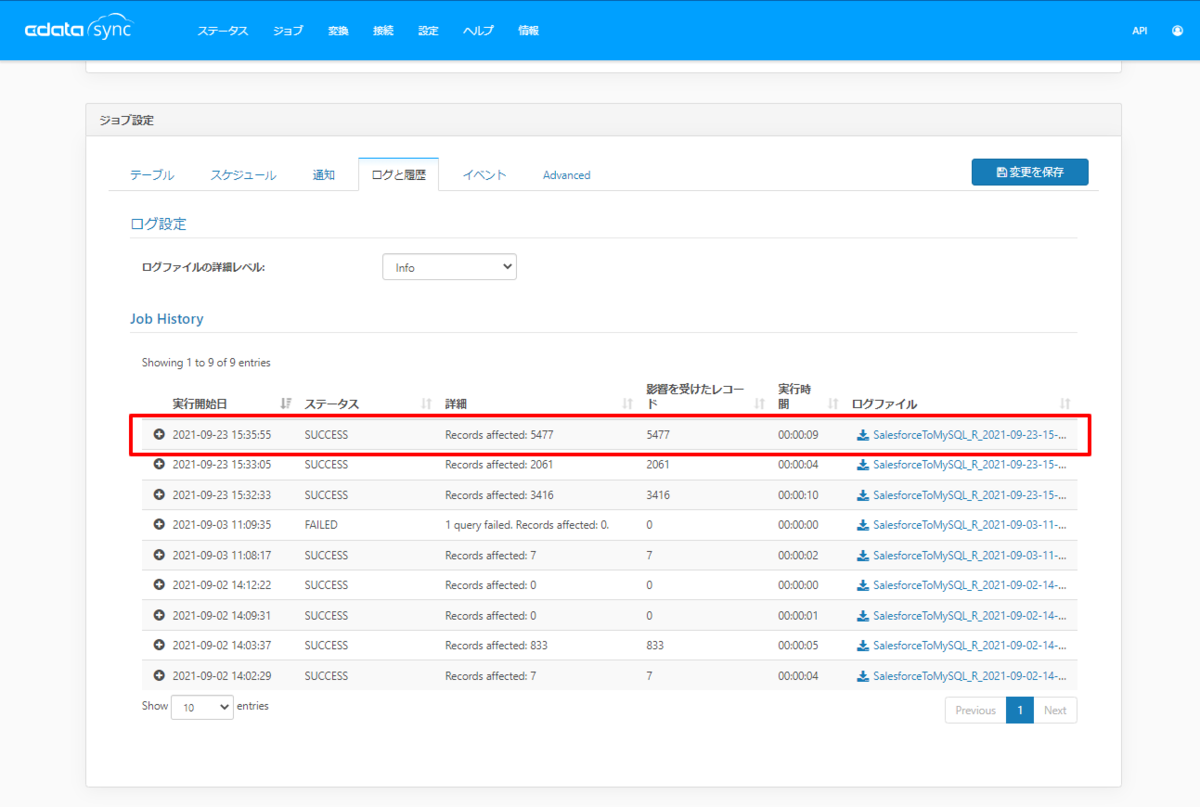
まずは並列処理は加えずに、通常通り実行してみました。
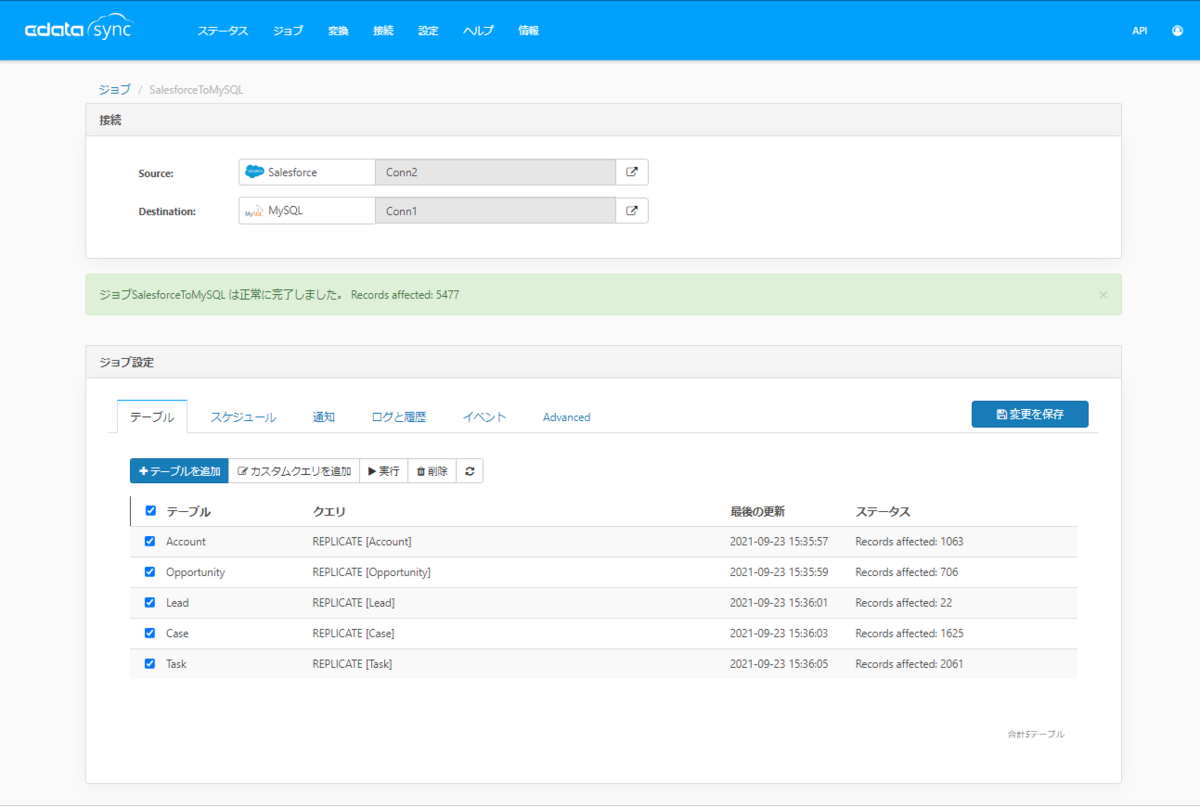
処理結果はログ上で確認できます。約5千レコードを実行するのに9秒かかりました。
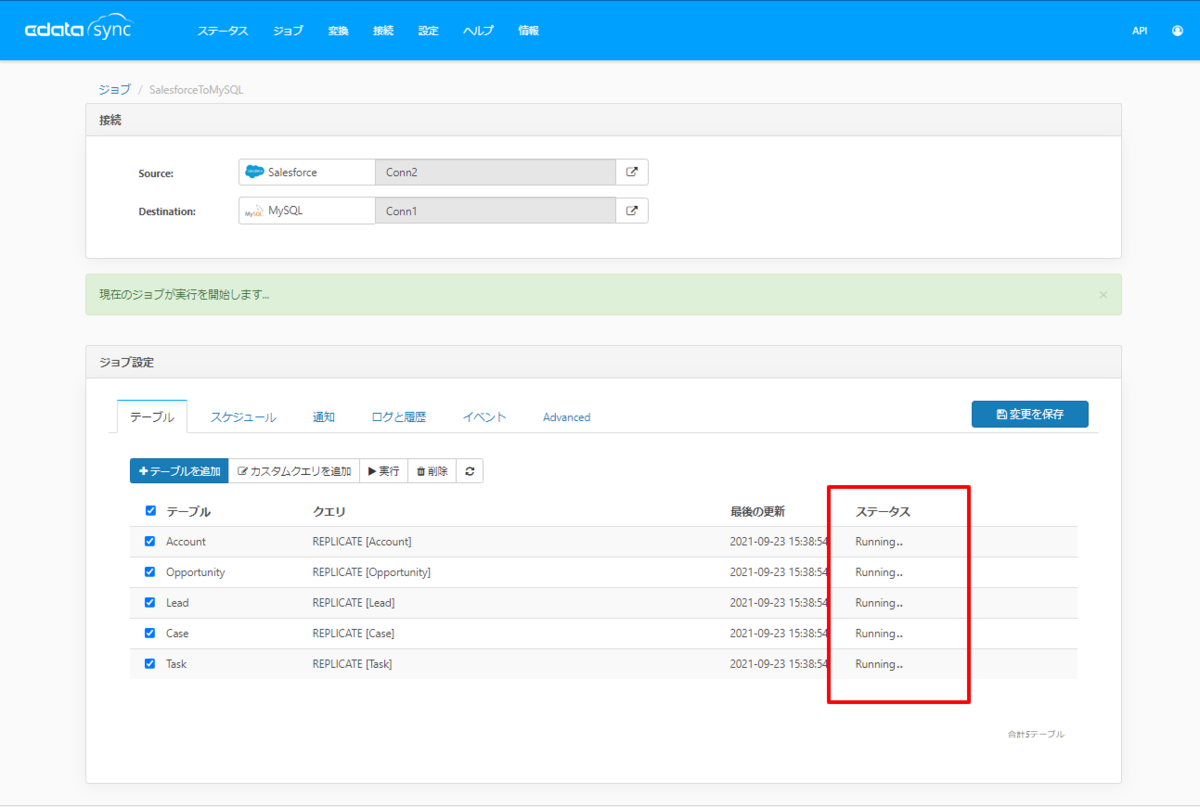
続いて並列処理を有効化し、ワーカープールに5を指定してみます。
手動実行を開始すると、すぐ違いが見て取れます。
通常であれば一つ一つステータスが「Running」に移り変わっていくのですが、5つのテーブル全部が一気に「Running」状態になりました。
ジョブの終了後、同じように処理結果を確認してみると、「5秒」とおよそ半分の結果になりました。
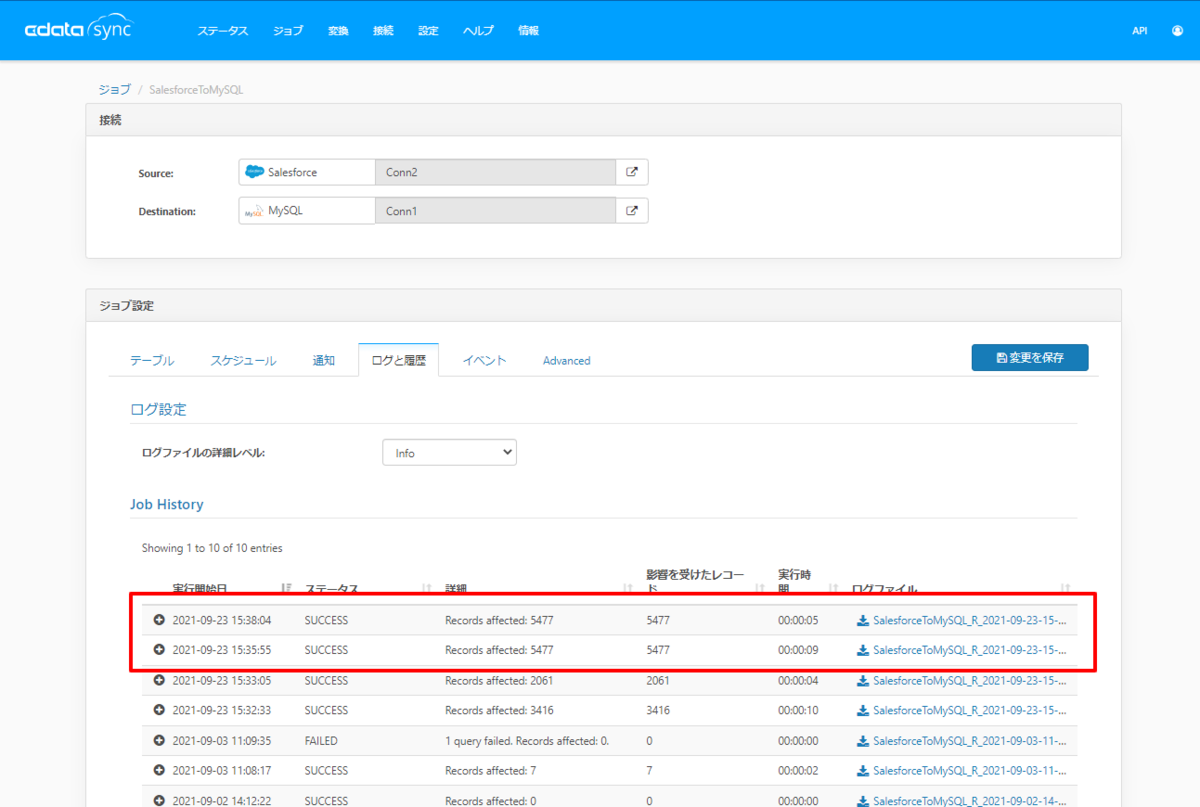
今回はわかりやすい数のテーブルのレプリケーションでしたが、対象のテーブルが増えるほど効果を発揮するでしょう。
並列処理レプリケーションで注意したいこと
さて、この機能はとても便利なのですが、CData Sync で取得するデータソースがSaaS APIなどの場合は、対象のサービスのAPI制限に抵触する可能性があるので注意が必要です。
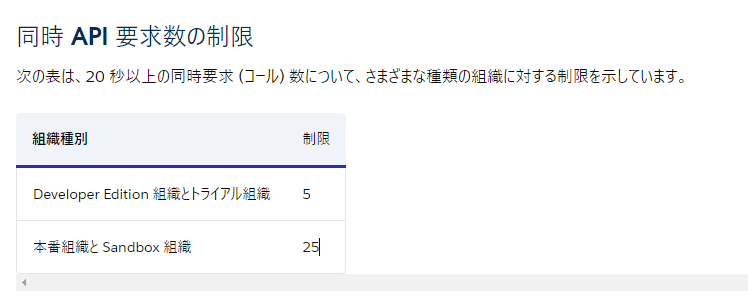
特に同時リクエスト制限が設けられているAPIは抵触してしまう可能性が高いでしょう。
例えば、Salesforce APIの場合は同時APIの要求数がDeveloper Edition組織もしくはトライアル組織の場合は「5」で、本番環境やSandbox環境の場合は「25」です。
もしテーブル数が増大する場合は、スレッドプールの数を抑えるか、並列処理は有効化せず、シリアルかつ、必要に応じてジョブとジョブの実行間隔も開けながら、利用していただくのが良いものと思います。