
こんにちは。CData Software Japan リードエンジニアの杉本です。
みなさんAPI連携されていますか? あるレポートによると昨今一つの企業が利用している平均のSaaSの数が80にもなっているらしいですね。これだけ様々なサービスにビジネスデータが散在していることを考えると、すべての企業にとってAPI連携というのは重要なファクターと言えるのではないでしょうか?
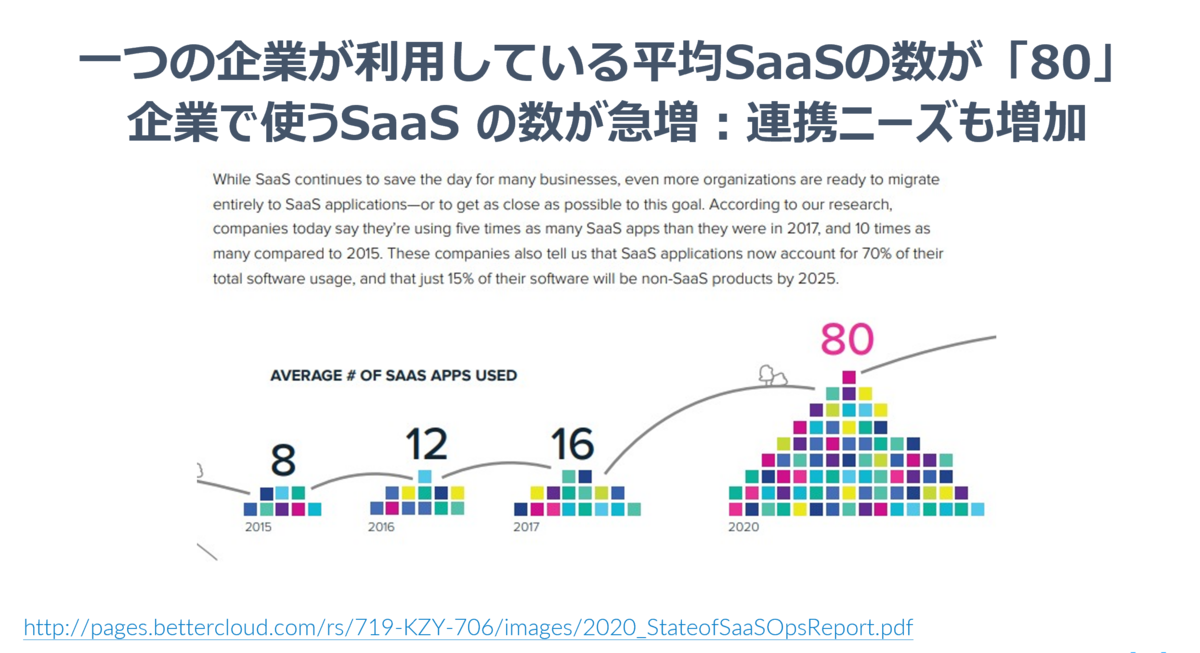
http://pages.bettercloud.com/rs/719-KZY-706/images/2020_StateofSaaSOpsReport.pdf
また、アプリ・SaaSを提供する側にとっても、この周辺SaaSとの連携というのは重要性を増しているでしょう。
以下はHubSpotとfreeeのプレスリリースを持ってきたものですが、1SaaSの中で展開されているアプリマーケット、APIを活用した連携アプリの数がどんどん増えているという数字です。HubSpotは500件、2年前にリリースされたばかりのfreeeでも100件を突破しています。
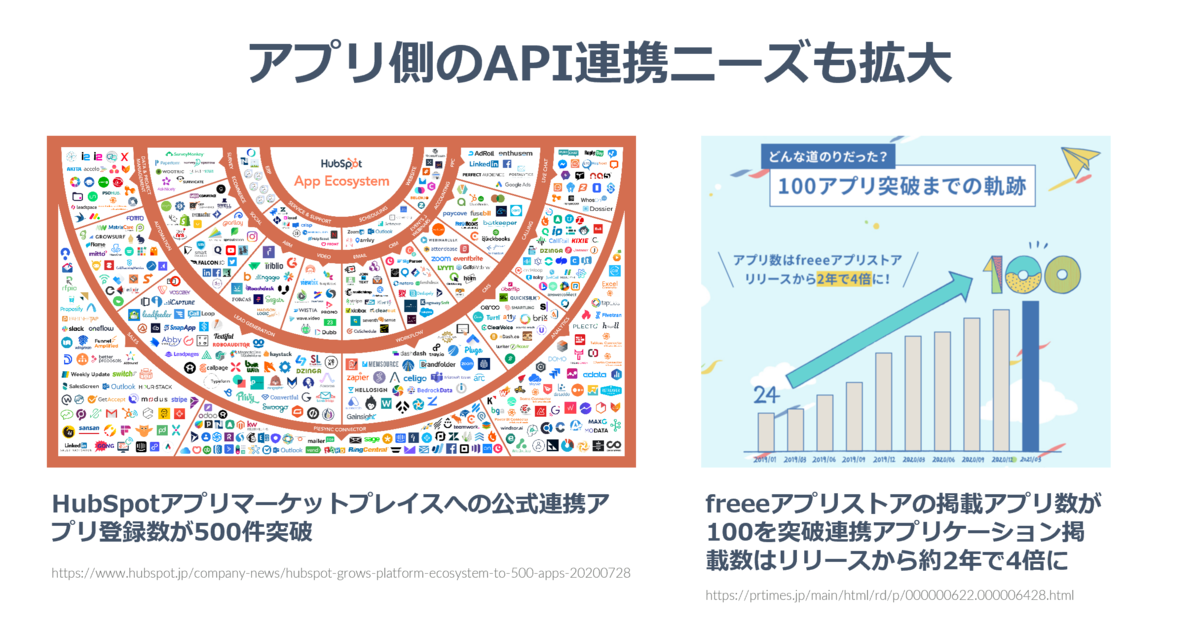
こういった視点からも、API連携という文脈がどんどんビジネスに浸透してきていることがよくわかるなと思います。
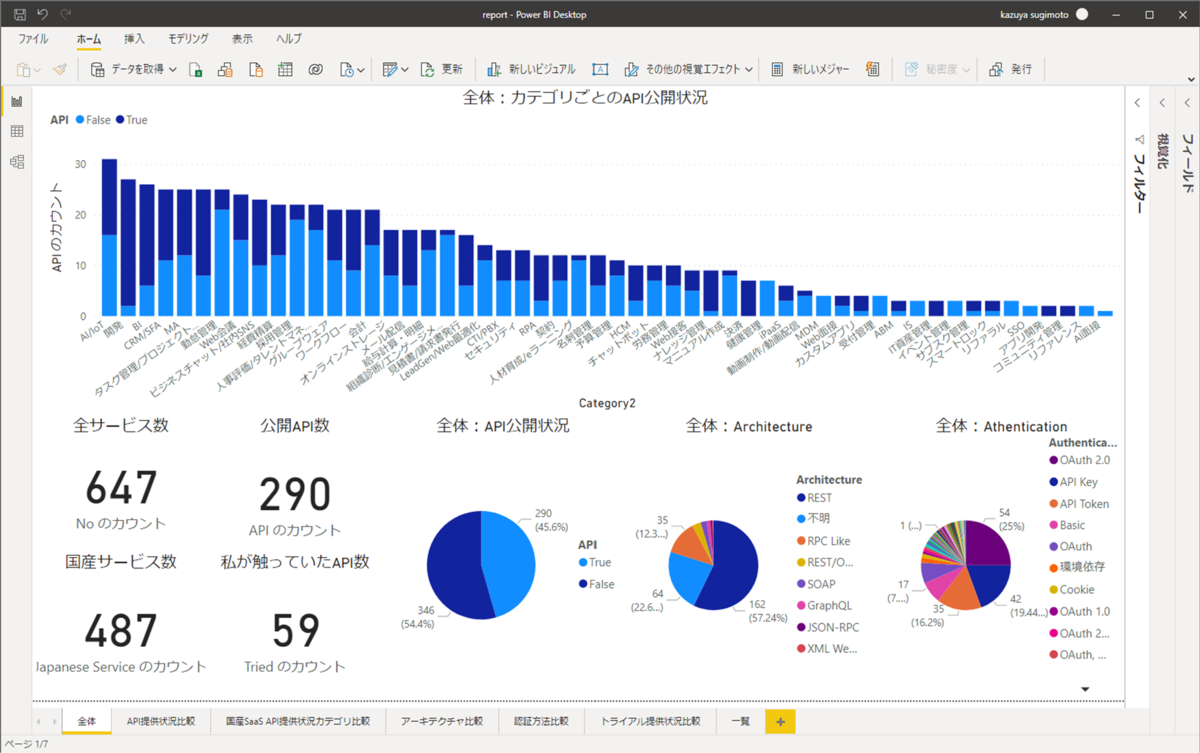
しかしながら、ちょっと見ていただきたいグラフがあります。
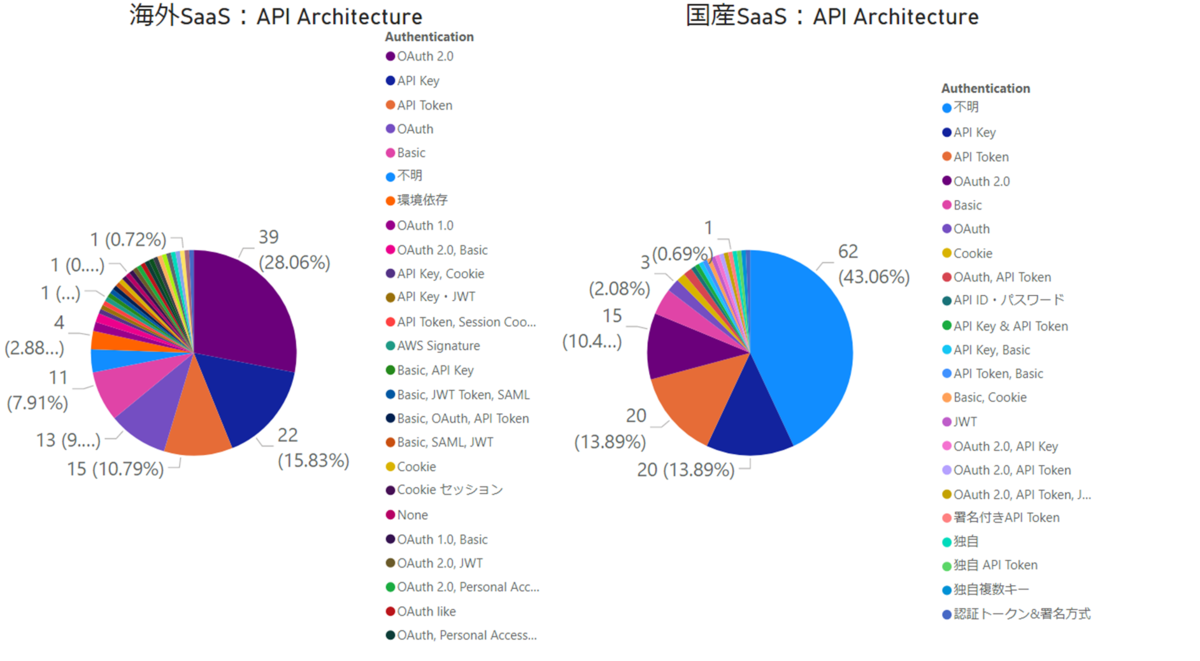
これは私が以前 SaaS APIの調査をしたときのデータなんですが、ここでなかなか興味深いデータが見えています。
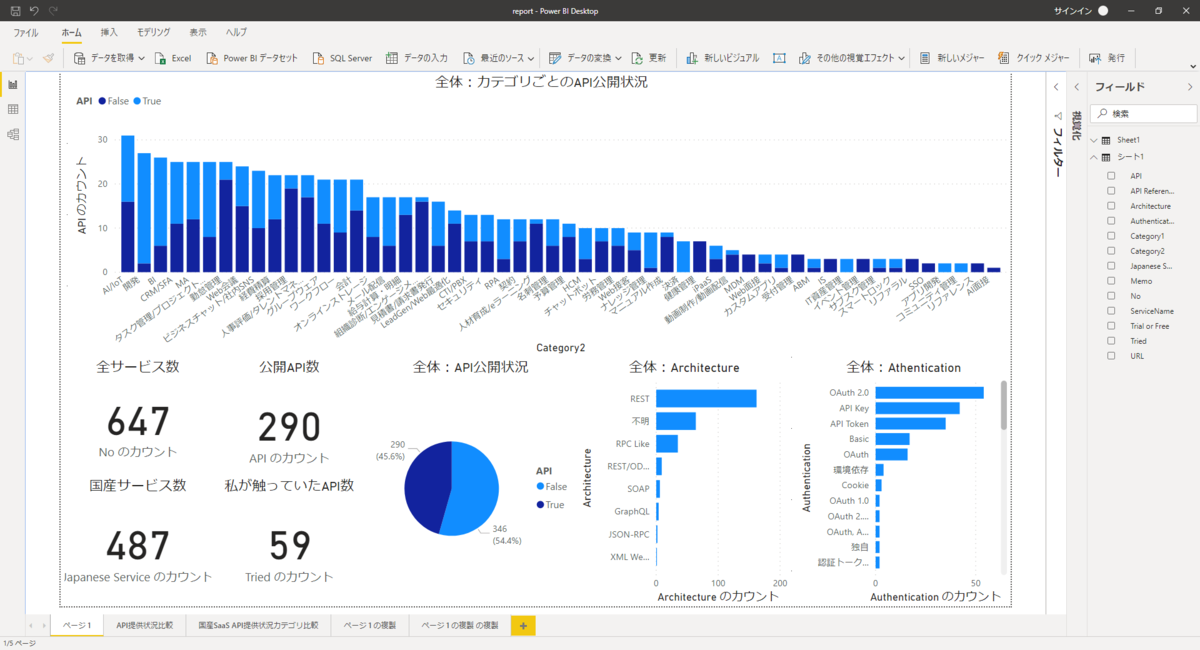
Horizontal SaaS カオスマップで公開されていた全647種類のSaaSのうち、およそ半数近くの290サービスがAPIを公開しているという数字ですね。
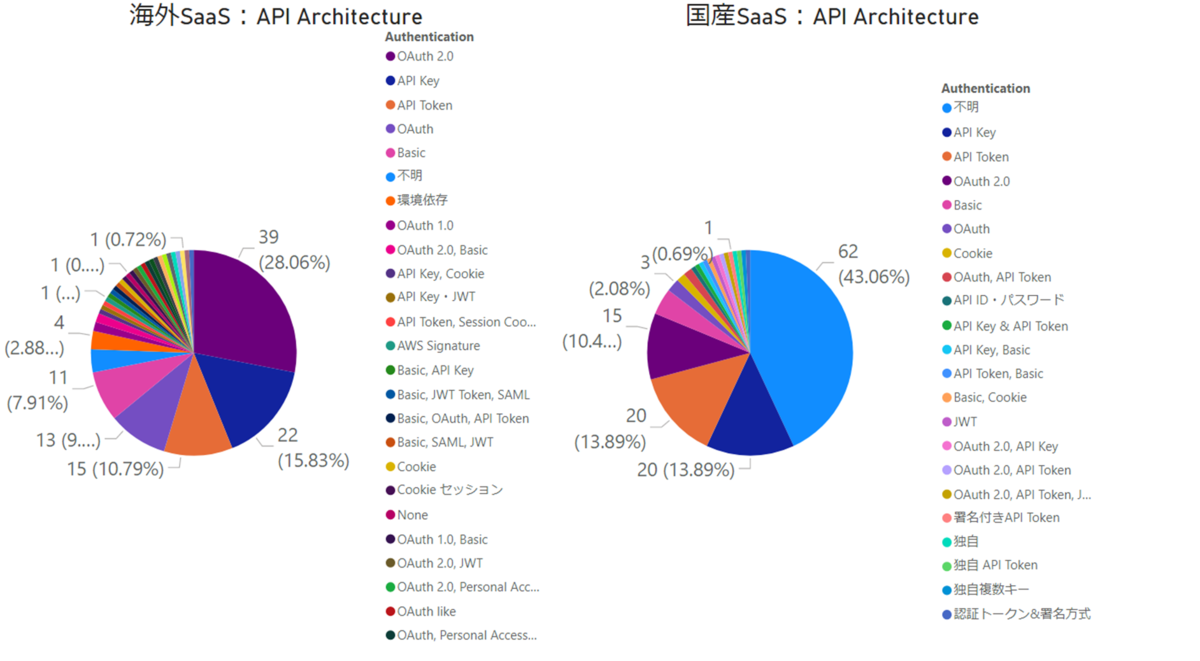
このデータで今回注目したいのは「それぞれのAPIでどのようなスタイルが使われているのか?」というグラフです。パッと見「REST」で作られたAPIが多いのですが、なんと国産SaaSでは4割が正体不明、2割がRPC Likeな独自仕様のAPIなんですね。
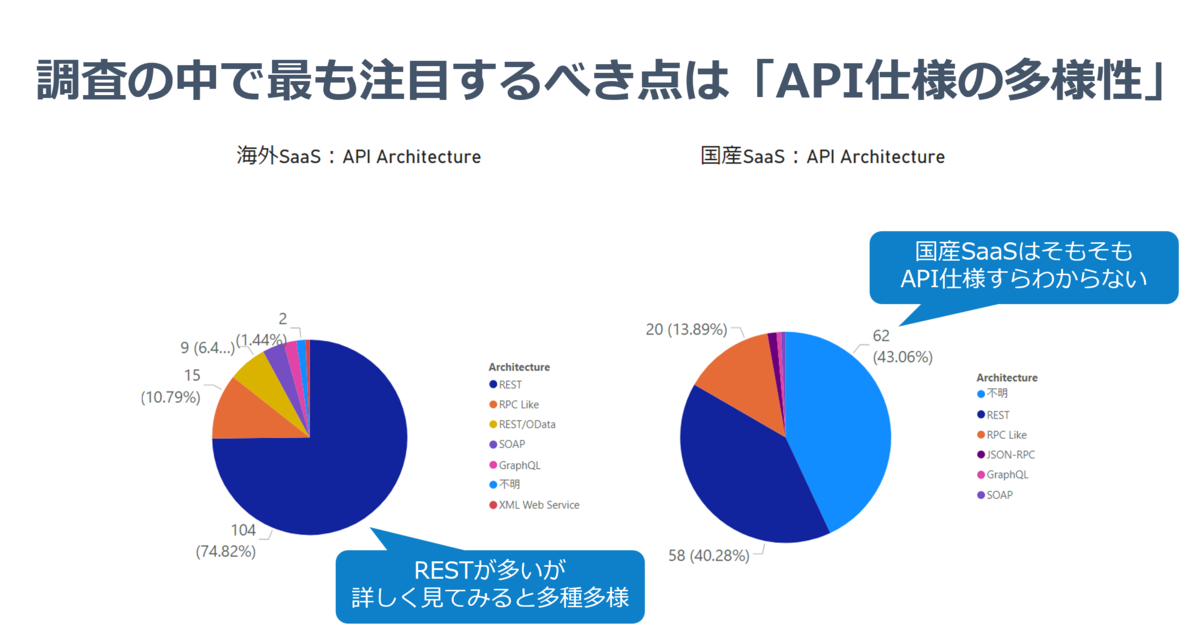
認証方法にも目を向けてみると、OAuth 2.0 がそれなりの割合を締めているものの、なかなか多様なラインナップであることが見て取れます。
CData Software ではこのようなSaaS のデータをDWHやRDBに転送するデータパイプラインサービスを提供しており、現在およそ400種類ほどのSaaSやNoSQL APIをサポートしています。

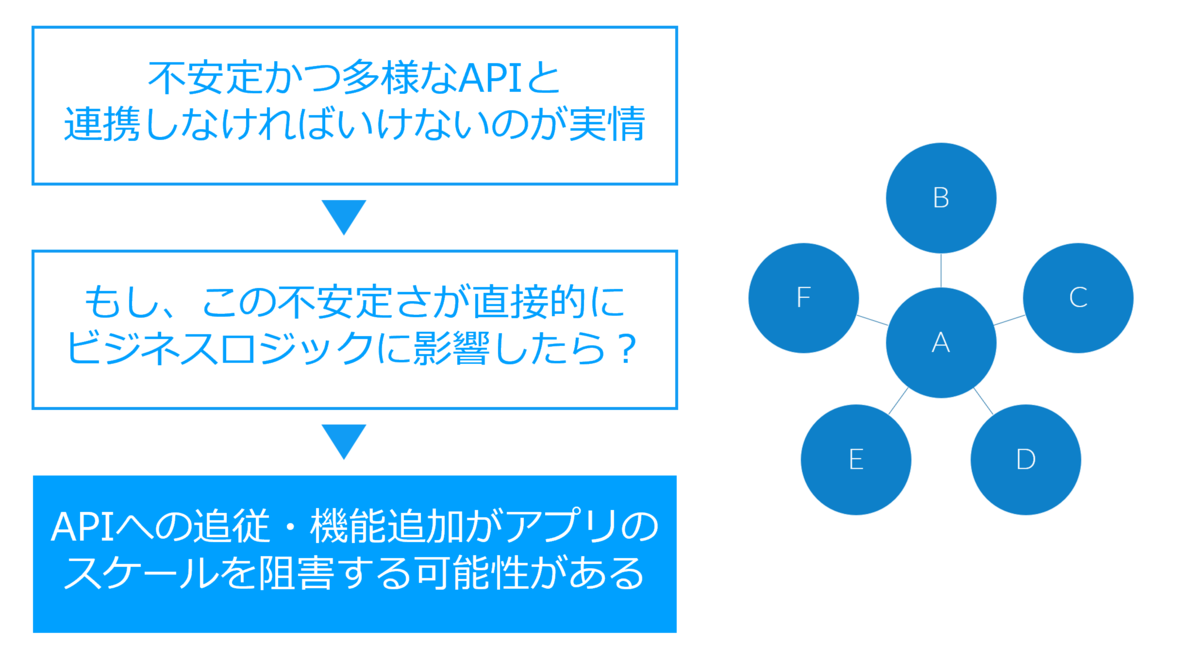
しかしながら、今述べたようにAPIというのは種類も千差万別かつ外部サービスゆえにコントロールがしづらい、突然アップデートがあるといった様相で、なかなか不安定極まりないもので、それを継続的にサポートしつつ、サービスとしてスケールさせていくのはなかなか大変な部分が多いです。
そうなんです。私達は「不安定かつ多様なAPIと共存している」、そして「共存しながらビジネス、システムを展開していかなければいけない時代」になっているわけですね。
前述の通り、API連携が普遍的な存在になっている今、このようなAPI連携の側面は私達のようなプロダクトサービスだけでなく、非IT企業の情報システム部門やSI、SaaSベンダーにとっても現在同じ状況ではないでしょうか?
昨今のクラウドサービスや社内アプリで「外部APIと連携したい」という需要は日増しに強まっているのが、開発者の皆さんの中でもはっきりと認識されているのではないかなと思います。
しかし、この外部サービスとの連携の不安定さがもし自社のビジネスロジックに、業務に影響したらどうでしょうか? アプリ、そしてビジネスの両面においてスケールを阻害する可能性があると言えるでしょう。
今回のこの記事では、こういった不安定かつ多様なAPIの連携に対してCData Software はどのようにプロダクトとして臨んでいるのか? どうやって400種類かつまだまだ増え続ける連携先を組織的に対応しているのか?
製品としての取り組み方、アーキテクチャを軸として解説していきたいと思います。

ちなみにこの記事はJJUG CCC 2021 Fallで発表した内容をベースに作成しています。(どちらかといえば、記事を書いてからスライドやセッションに起こしているので、こちらが先なんですが)
大量のAPIサポートしつつ、スケールするアーキテクチャとは?
はじめに結論から入ってしまいましょう。
どうやってこんなに大量のAPIサポートしつつ、かつスケールしているのか?

と考えています。
なぜなら
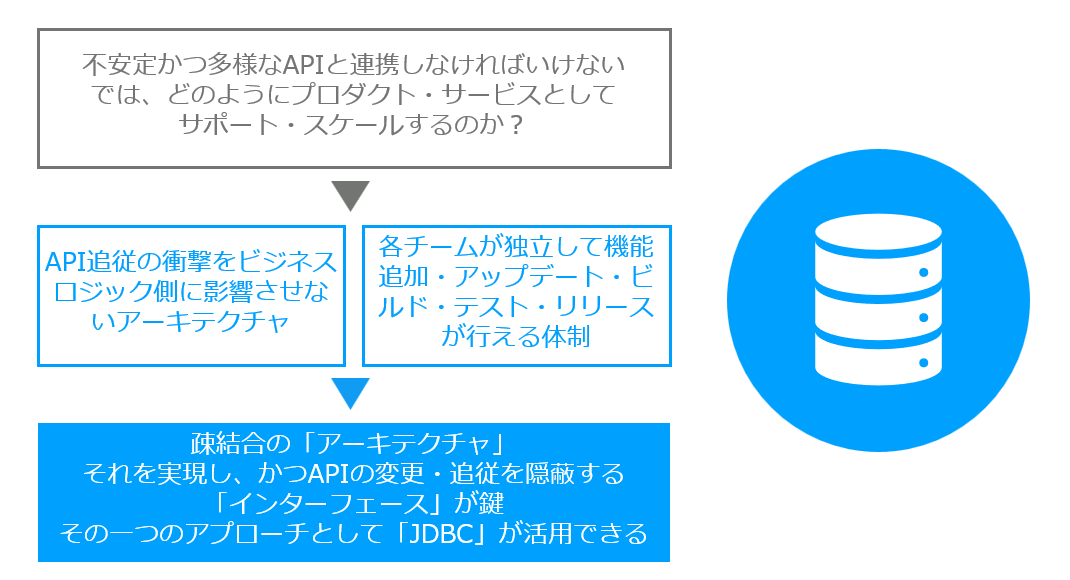
「API追従の衝撃をビジネスロジック側に影響させないアーキテクチャ」
「各チームが独立して、それぞれ機能追加アップデート・ビルド・テスト・リリースが行える体制」
がスケールするための要だからにほかなりません。
はっきり言ってしまえばスケールを阻害する要因は「密結合」です。
改めて「密結合」ってなんだっけ?と見直してみると、以下の引用がわかりやすいですね。
密結合とは、細分化された個々のコンポーネント同士が密接に結びついている状態のことである。 密結合状態のシステムでは、緊密で高速な動作が可能となっているが、一方のコンポーネントが異常をきたすと、他方のコンポーネントがその影響を受けてしまう。 そのため密結合のシステムでは、保守や部品の交換などに際して密接な連携を顧慮する必要がある。 密結合はマルチプロセッサシステムのようなハードウェア的なものから、アプリケーションソフトのようなソフトウェア的なものまで、幅広く見られる状態である。
APIへの追従に他のモジュールが影響を受けやすいとメンテナンスコストの増加を招き、「スケールを阻害」してしまうんですね。
あるチームがAPI Updateに追従して行った修正が、他のチームのモジュールに影響して、対応範囲が実は広大に及んでいた、ということはありませんか。そういうことがあると、なかなかプロダクトとしてはメンテナンスコストばかりが嵩んでしまい、スケールしづらくなってしまいます。
特に自分たちではコントロールしようが無い、外部サービスに依存してしまうからこそ、よりこの密結合の弊害がビジネス側に影響を及ぼしやすくなっていると考えることができるでしょう。
だからこそ、より「疎結合」なアーキテクチャの重要性が増していると考えることができます。
それでは、CDataの製品、CData Sync ではこの外部のAPIに対してどのようにアーキテクチャレベルで対応しているのでしょうか?
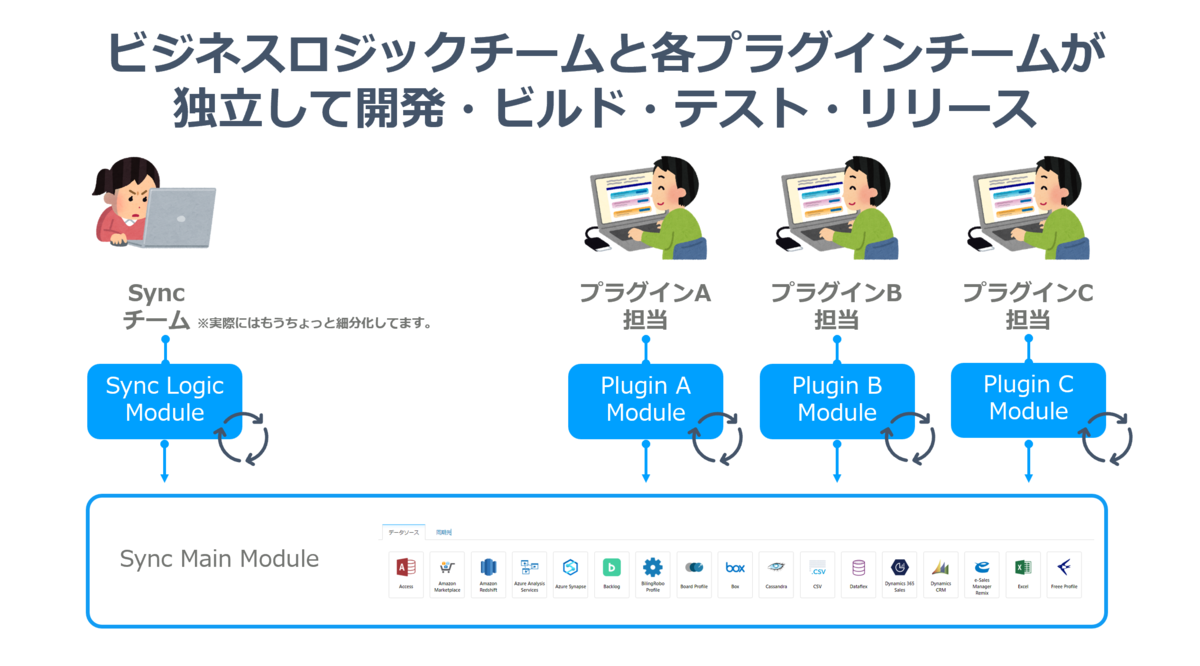
実は結構シンプルで CData Sync はデータパイプラインを担うビジネスロジックレイヤーとAPIからデータを取り出す、やり取りをするプラグインレイヤーに分けたアーキテクチャを構成することにより、疎結合性を実現しています。(UIとかも含めるともうちょっと細かく分けることができますが、今回はここだけ)
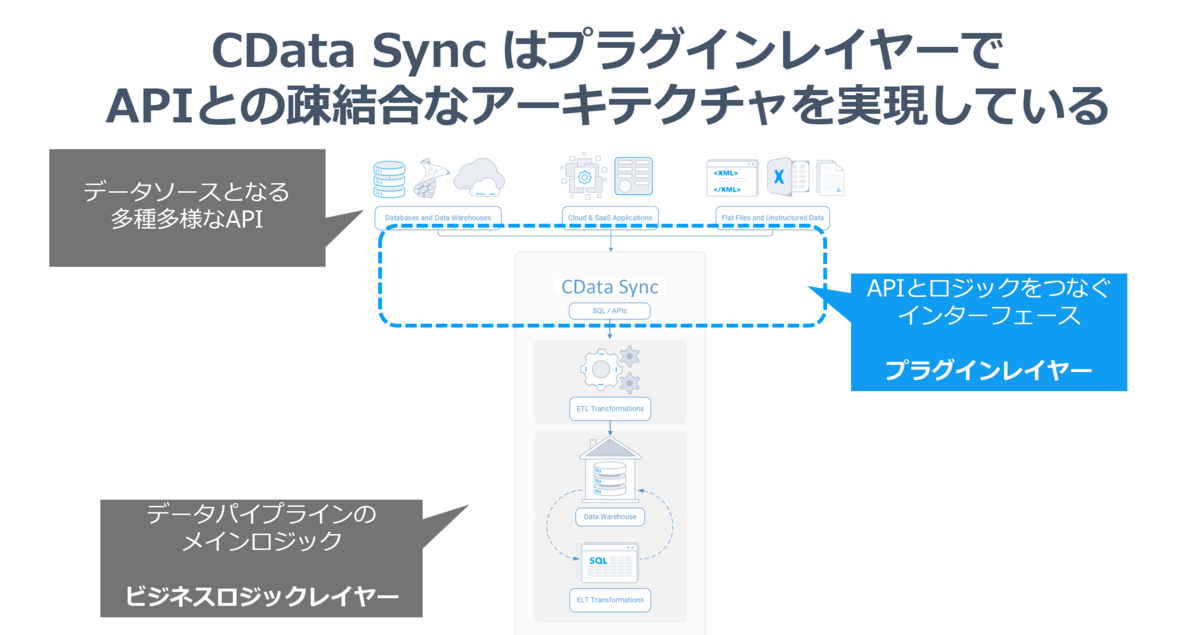
プラグインレイヤーの各種プラグインはAPIとの連携を行うインターフェースの実装のみに注力します。そして、ビジネスロジックレイヤーはすべてのプラグインレイヤーで共通したインターフェースを利用して、データパイプラインの処理に注力します。
このアーキテクチャによりビジネスロジックレイヤーは一切、API側の仕様のゆらぎは意識せず、共通したインターフェースで扱えることにより、それぞれ独立したチームとして動けるようになっています。
さらに各APIごとのプラグインも独立して開発・ビルド・テスト・リリースまでできるようになっており、これにより大量APIプラグインの並行開発・リリース・メンテナンスを実現しています!
では、その疎結合なアーキテクチャを 実現している「インターフェース」とはなんなのか?

実は古くから存在する皆さんにも馴染み深いAPIである「JDBC」を採用しているのが、CData Syncの大きな特徴なのです。

そうRDBに接続して、SQLをクエリするためのインターフェース、JDBCです。
そのインターフェースを如何に活用し、如何に実装し、如何に維持しているのか? 深く見ていきたいと思います。
API仕様のガラパゴスな世界と常に変わり続ける仕様への追従
とはいえ、具体的な話に入る前に、まず昨今のAPI連携が求められる環境について、もう少し皆さんと認識を共有しておきましょう。
前述した通り、現在私達は多種多様なAPIの世界で連携・開発を行っている状況であるとお話しました。
一度にこのAPIのスケールを意識し・拡張性を踏まえながらサービスに機能を組み込もうとすると、2つの壁に衝突します。
それが「多種多様なAPI仕様」「変わり続けるAPI仕様」という壁です。

「API、APIって言いながら、ほとんどがREST APIなんじゃないの?」みたいな話も聞きますが、そこも大きな落とし穴でしょう。
おそらく皆さんが数多く遭遇するであろう、「REST API」なるものは、いざ触ってみると規格と呼べるようなものではなく、それぞれ独自のインターフェースであることを知ります。
SFTPやSMTPといったプロトコルほど強固な規格ではなく、各ベンダーが独自に構成しているREST APIちっくな何かであることがほとんどです。
そもそもRESTとは「Web API を REST たらしめる“原則“」であり、規約レベルほど強固なものではありません。
REST = Representational State Transfer
Representational State Transfer (REST) は、ウェブのような分散ハイパーメディアシステムのためのソフトウェアアーキテクチャのスタイルのひとつである。

例えば Salesforce でも REST APIが提供されているので、一見扱いやすいように見えますが、実体はSOQLというSalesforce内部での独自規格のSQLを発行するAPIになっていたりします。
それぞれのAPIの良し悪しについて述べたいわけではありません。これだけ多様なAPIが溢れているということを認識した上で、取り組まなければいけないわけです。
さらに、この多様性はAPIのデザインだけに留まりません。
皆さんがAPIを試すにあたって最初に突破しなければいけない「認証」にまつわる点もそうでしょう。
Web APIの認証にまつわるアプローチの多様性には驚かされるばかりです。
また、同じ OAuth2.0 であったとしても、内部で細かな挙動の違いがあったりしますね。
例えばAzure ADでのOAuth 2.0、リフレッシュトークンの取得アプローチは以下のようになっていて、新しいRefresh Tokenが都度発行されます。しかしながら、Google Cloud Platform の OAuth 2.0 だとリフレッシュトークンは永続的なもので、再発行されなかったりします。

さらに「API仕様の変更」はAPI連携製品・サービスを提供している会社にとっては切っても切れない重要なファクターですね。
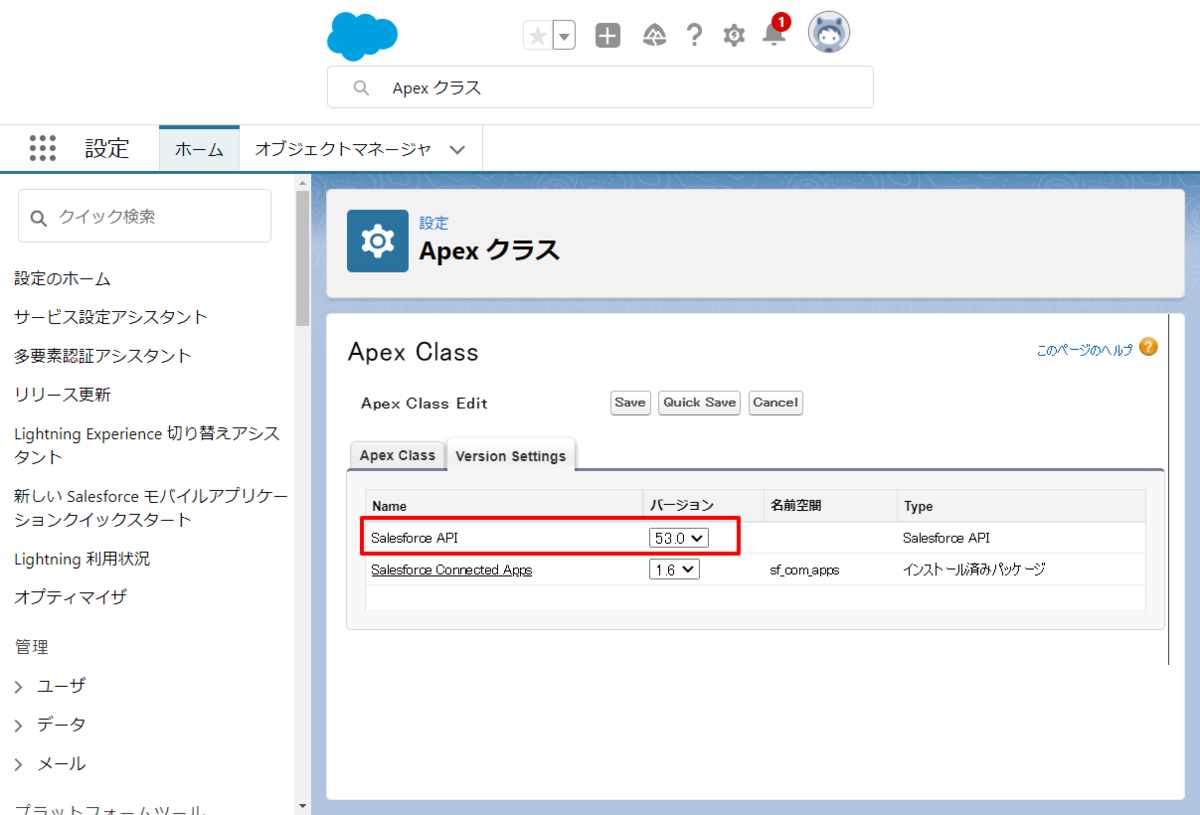
皆さん Salesforce の APIバージョンって今いくつかご存知ですか? なんと「53」なんですね。年に数回のアップデートがあり、古いバージョンのサポート終了もどんどん進んでいます。
とはいえ、Salesforce APIは毎回大きく機能が変わるわけではありません。(もちろん、認証周りなどの大きな変更がある時はありますが・・・)
もうちょっと実例ベースでいくと、弊社でも最近対応したAmazon Marketplace APIの変更がビックチェンジでした。
今まで利用できたMWS APIというXMLのRPCライクなAPIから、REST ful なAPIに変更されるというものです。ちなみに、このAPIの公開は2020年半ばだったのですが、2021年4月に突如「半年後の9月30日で古いAPIを終了するよ、早く切り替えてね」という告知が出回ったのも衝撃的でした。(※現在は2022年7月に延期)
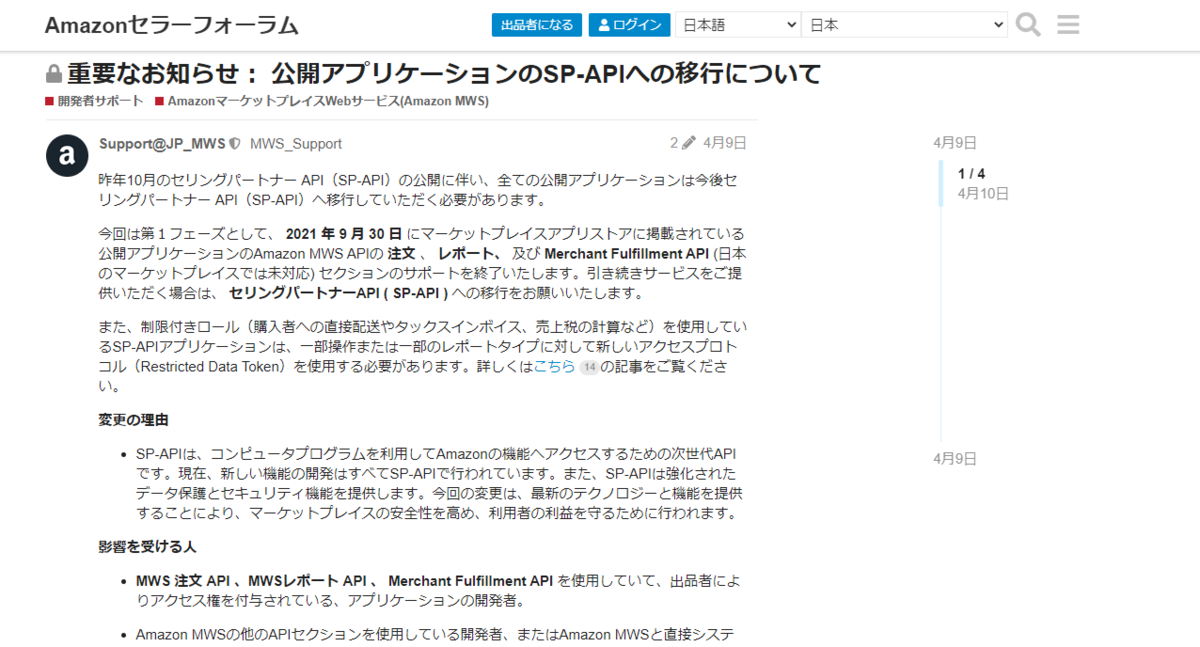
認証方法も独自の方式からOAuth 2.0 とAWS IAM混合のこれまたユニークな方式に変わり、レスポンスフォーマットもXMLからJSONになりました。恐ろしいですね。

そういえば消費税率・軽減税率対応はEC周りやモール関係のAPIでは大きな変更がありましたね。このあたりは経験された方も多いのではないでしょうか。
Yahoo Shoppingなどのモール系サービスでは軒並みエンドポイントに手が入りましたね。中の方々も大変だったかとは思いますが。
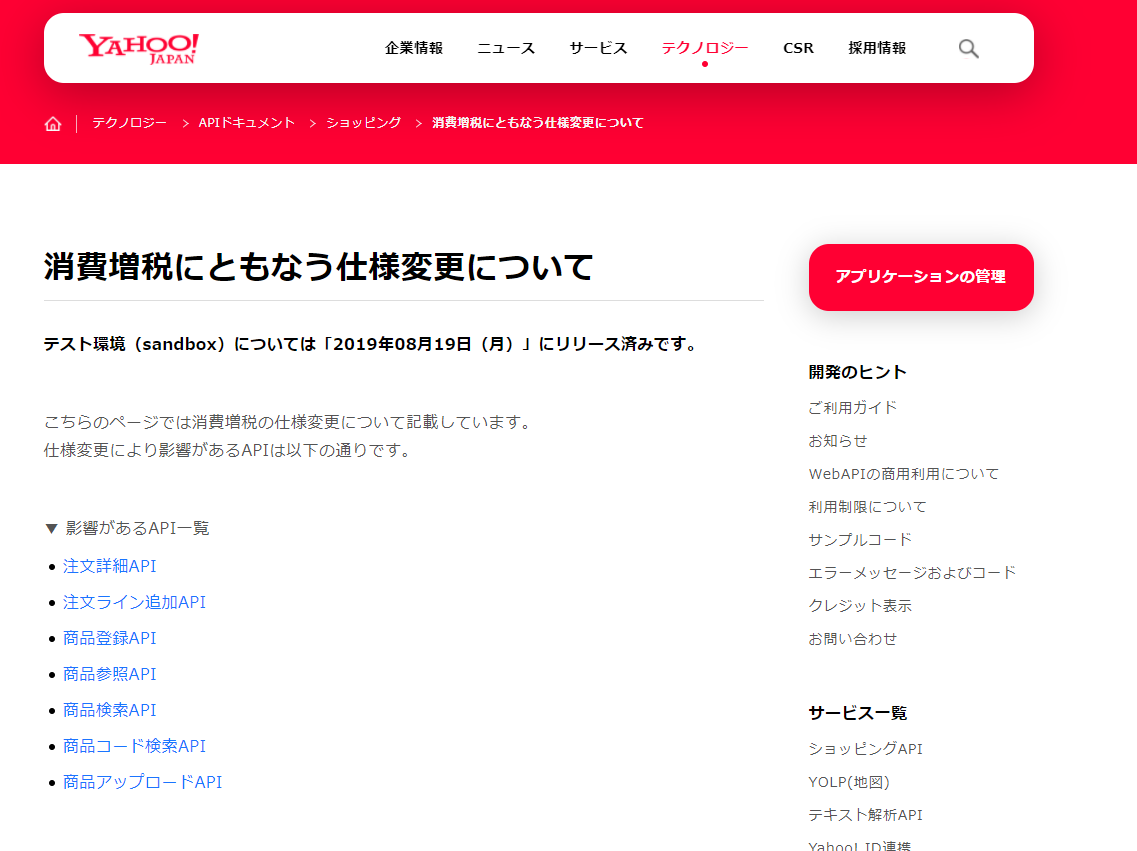
いくつか例としてとりあげてみましたが、このように不安定かつ多様なAPIを相手にしなければいけないのが、残念ながら実情になっています。
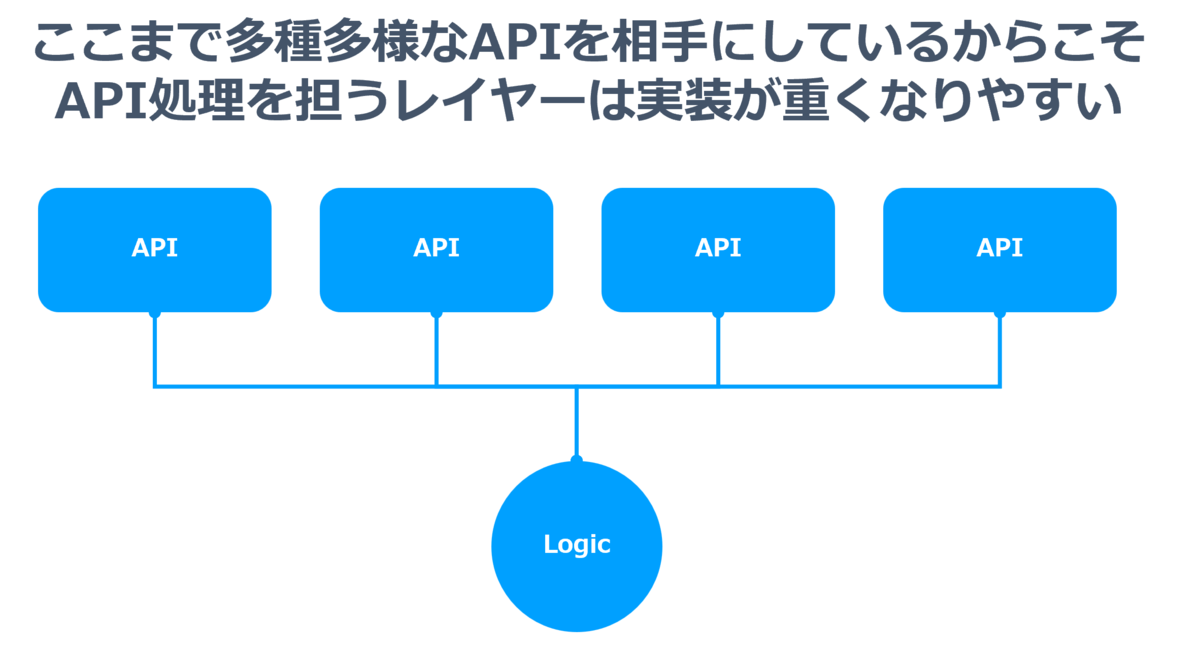
もし、ビジネスロジックとAPI連携が密結合であれば、APIのアップデート・追従・機能追加がもろにサービスやアプリケーションのアーキテクチャを破壊してしまう可能性があるのです。
だからこそ疎結合の「アーキテクチャ」とそれを実現し、かつAPIの変更・追従を隠蔽する「インターフェース」が超重要なわけですね。
CData Syncはどうやってこれだけのスケールとサポートを維持しているのか?
それでは本題に入りましょう。CData Syncはどうやってこれだけのスケールとサポートを維持しているのか?
最初に述べたとおりプラグインアーキテクチャで疎結合に構成しJDBCインターフェースでAPI追従の衝撃を緩和するという製品の開発戦略を取っています。
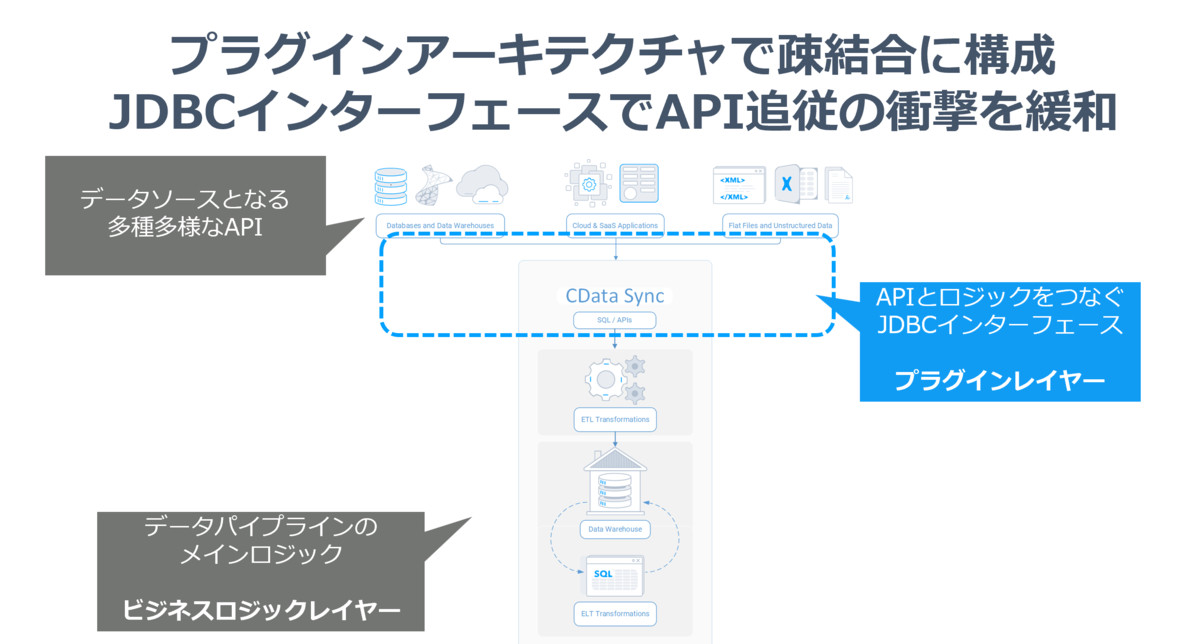
このような疎結合アーキテクチャにすることで、Sync 本体の基本的価値となるデータパイプラインとしての機能強化・UI等の機能強化と付加価値となっているAPI追従対応・追加データソースの開発対応のスピード感・メンテナンス性を両立させています。
プラグインは独立したjarファイルのライブラリ形式にしており、これを外部から差し込むことで、追加データソースとしてラインナップされます。もちろんユーザーはjarファイルが差し込まれているとは普段意識することはなく、コネクタといった形でダウンロードしてくるだけです。
中身はこんな感じですね。
ちなみに、CData の製品を触ったことがある方であればご存知だと思いますが、このjarファイルは個別製品としても提供されています。
ちなみにだいたい各プラグインには開発・メンテナンス担当となるOwnerが居て、1担当が複数のPluginを常に見ています。
そしてここで最もユニークな点は、Sync本体チームとPluginチームで、「新しいPluginの追加やAPIの追従におけるコミュニケーションがほぼ発生しない」という点です。プロジェクトスタイルとしても、完全に非同期的に動いていて、Syncはスプリントベースですが、Pluginはウォーターフォール的に個別に開発されています。ハイブリッドですね。
SyncチームはどんなPluginが追加されているか、更新されているかほぼ意識しません。また、PluginチームもSyncにどのような機能が追加されているかも意識しません。もちろん、マーケティング目線では協力したり、リクエストが飛び交っていたりしますが。
これは情報交換やコミュニケーションが一切無いのではなく、独立したチームとして動けるということを示しています。
さて、ここまではわりかしよくあるプラグインアーキテクチャだと思いますが、このプラグインアーキテクチャを実現する上でCDataのビジネス上最も大きなポイントになっている部分が「インターフェース」のデザインです。
なぜCData はこのプラグインアーキテクチャにおいて「JDBC」というインターフェースを採用しているのでしょうか?
ここが最も大事な部分なんですが、良い疎結合の実現には堅牢なインターフェースデザインの採用がポイントになると考えています。
グラグラするインターフェースは疎結合を阻害します。そもそもAPI側がグラグラしているんですから、それをしっかり受け止められるインターフェースで無ければ、ビジネスロジックおよびその周辺に被害が広がってしまいます。
皆さん感じる部分だと思うんですが、プロダクトの成長・スケールを見据えて、インターフェースのデザインを固めることは結構難しくないですか?

「インターフェース」の機能要件を決めきれないんですよね。このインターフェースはJavaによる実装でも、内部のマイクロサービス的なREST APIによる実装でも構いません。
例えばInterfaceにどのようなメソッドを定義するのか? 返り値や引数のデザインはどうするのか? どこまで機能をサポートするのか?

もしくは、REST APIを採用するにあたって、GET/POST/PUT/DELETEそれぞれのメソッドにどうデータモデルやビジネスモデルを当てはめるか? といった形でもありえるでしょう。
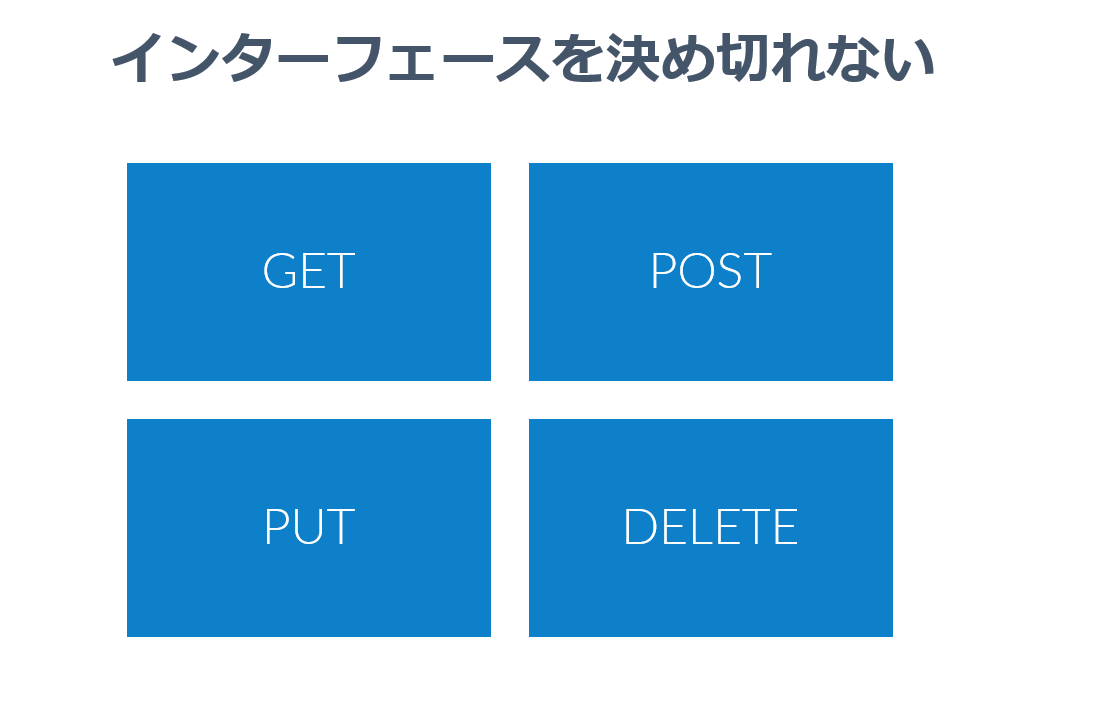
複雑なクエリを渡したいから、RESTから逸脱して、POSTリクエストで統一してしまうというパターンもあったりしますね。

また、プロダクトの成長・スケールを見据えて、インターフェースのデザインを固めることは結構難しくないでしょうか。
将来性を加味してインターフェースの仕様を柔軟にしすぎると、ロジック側の実装コストとプラグイン側の実装コストがかさみます。でも、固めすぎると追加機能対応に適応し難い。
そこで、CData では堅牢かつ柔軟なインターフェースとして前述の通り「JDBC」を採用しています。

え? JDBC? と思うかもしれません。 そう、あのOracleやMySQLといったRDBに接続するためのインターフェースであるJDBCです。
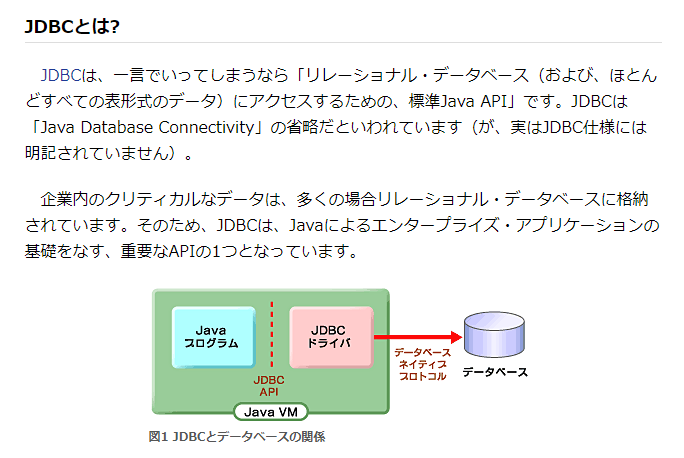
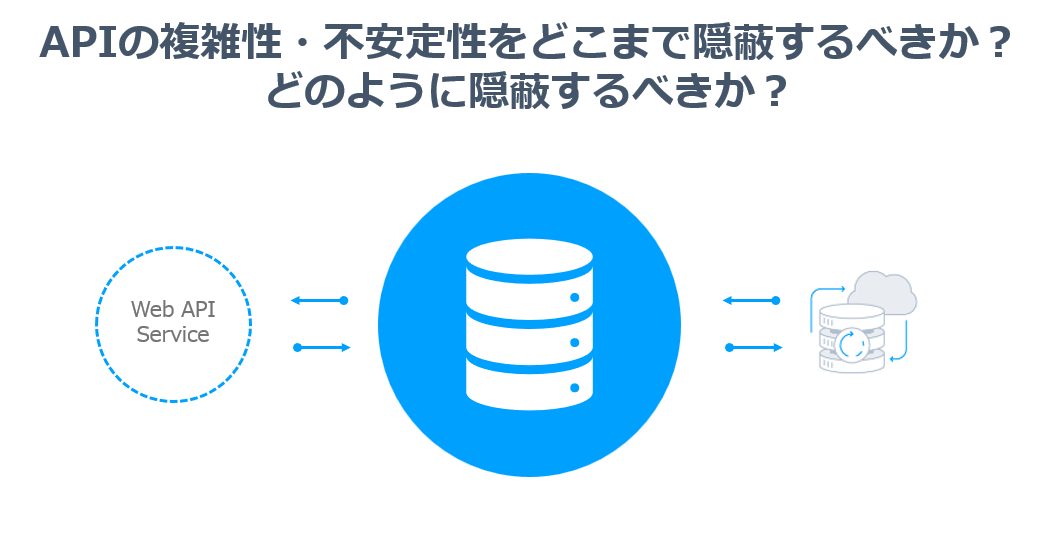
ざっと内部の仕様を図にすると以下のようになります。
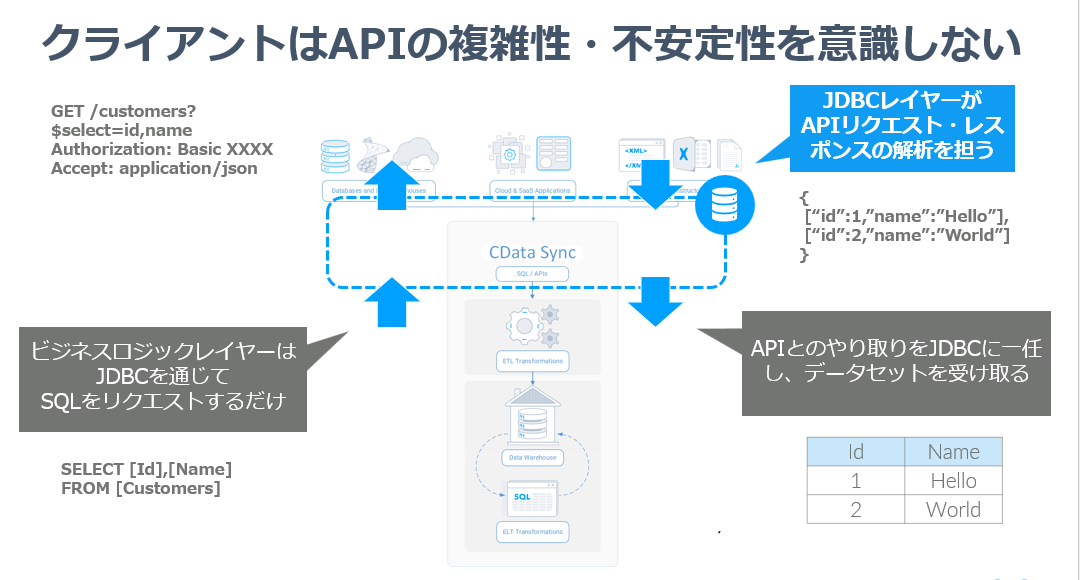
CData SyncのビジネスロジックレイヤーはJDBCのインターフェース・SQLの利用のみにフォーカスしています。どのプラグインからどのようにデータを取得するのか? はすべてSELECTのクエリをJDBCにわたすことで実現します。
そして、プラグインはそのSQL・SELECTクエリを解析し、APIリクエストに変換。取得したJSONなどのレスポンスデータをJDBC側のデータセットフォーマット、つまり表形式に変換して、ビジネスロジックレイヤーに返します。
これにより、クライアント側、つまりCData Syncのビジネスロジックレイヤーは一切APIの複雑性・不安定性を意識せず、RDBに接続するのと同じ文脈でAPIのリクエストを達成します。
このようなアーキテクチャを構成しているわけですが、JDBCを採用している具体的な理由としては以下の5点に集約されるかなと思っています。
RESTのようなゆるい規格ではない。スタンダードかつ認識の齟齬が発生しない、手続きがきまっている規格である。
クライアント側は汎用的な JDBC API の仕様のみを意識して実装できる。使い慣れたクエリ言語、接続定義が利用できる。
CData Sync というRDBライクなデータを扱う製品に向いている。
独立した利用・動作確認が安易かつ横断的なテスタビリティを確保しやすい。
1つ目と2つ目は共通的な文脈でもありますね。確立された仕様であるがゆえに、クライアント側・インターフェース側で齟齬が発生しないというのが、一番強みです。
ただ、これを採用できる最も大きなファクターはCData Syncがデータパイプラインという性質・ビジネスロジックの特徴を持っているからこそでもあります。
さらに隠れたポイントになっているのは実はMetadataの存在です。現状公開されている数多くのAPIはそのAPIの振る舞い・仕様を外部的に読み取るためのMetadataやスキーマ情報が存在しません。ようやくOpen API(Swagger)などを採用したAPIも増えてきましたが、まだまだそういったAPIは少ないなと感じます。
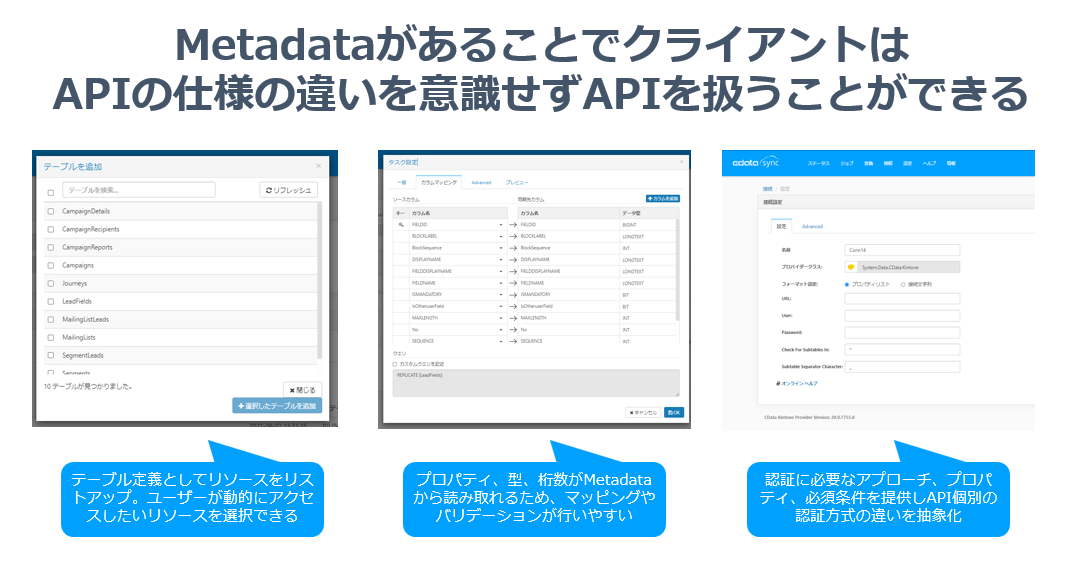
Metadataが存在することで何が嬉しいのか? といえば、クライアント側が利用できるリソースやレスポンスの型情報、必要なリクエスト情報が動的に把握できるという点に付きます。
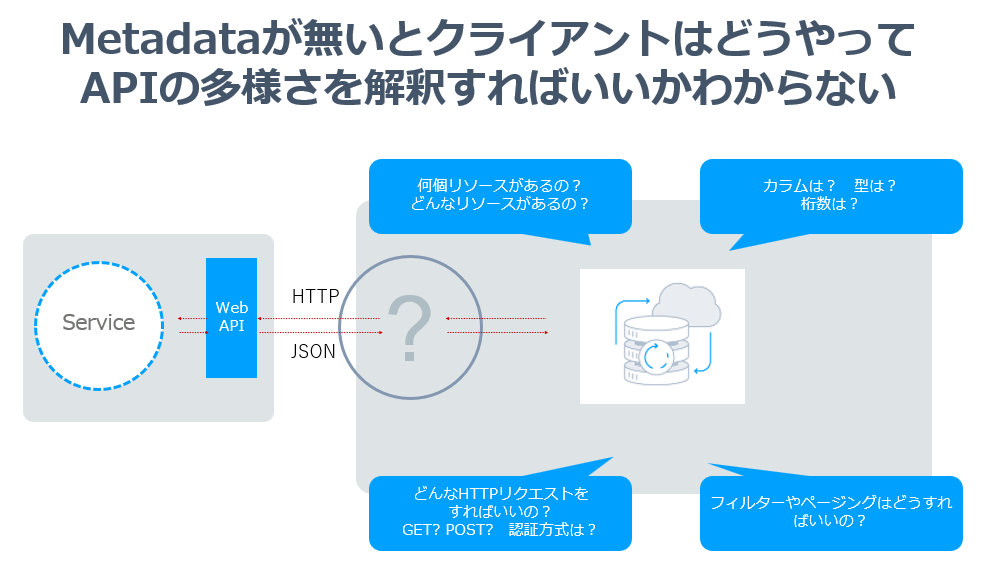
よくREST APIを触っていて、レスポンスのオブジェクトの型がよくわからなかったり、どうやってリクエストしたらいいのかわからないといったことがありませんか? それはすべて規格としてのゆるさ、APIの仕様を咀嚼するためのAPI・Metadataが存在しないということに他なりません。
JDBCであれば、以下のようにgetMetadataメソッドを用いて、対象のデータモデルの機能を読み取ることができます。
String connectionString = "jdbc:salesforce:User=myUser;Password=myPassword;Security Token=myToken;"; Connection conn = DriverManager.getConnection(connectionString); DatabaseMetaData table_meta = conn.getMetaData(); ResultSet rs=table_meta.getTables(null, null, "%", null); while(rs.next()){ System.out.println(rs.getString("TABLE_NAME")); }
このデータがあることで、CData Syncは各プラグインが持つリソース・データの一覧、項目の一覧を動的に読み取り、ユーザーエクスペリエンスの向上につなげています。これは多様に存在するAPIの認証周りの抽象化にも一役買っています。
また、最後の「独立した利用・動作確認が安易かつ横断的なテスタビリティを確保しやすい」というのも様々なシチュエーションで役立ってきます。
JDBCはそのスタンダードな規格性により、例えば外部ツールで独立して検証・動作確認を行うことができます。例えば、CData では JDBCのデバッグとしてDbVizualizerというDB接続ツールをよく用いています。これによりCData Syncという製品を通すことなく、独立してAPIの疎通検証・テストを行うことができます。
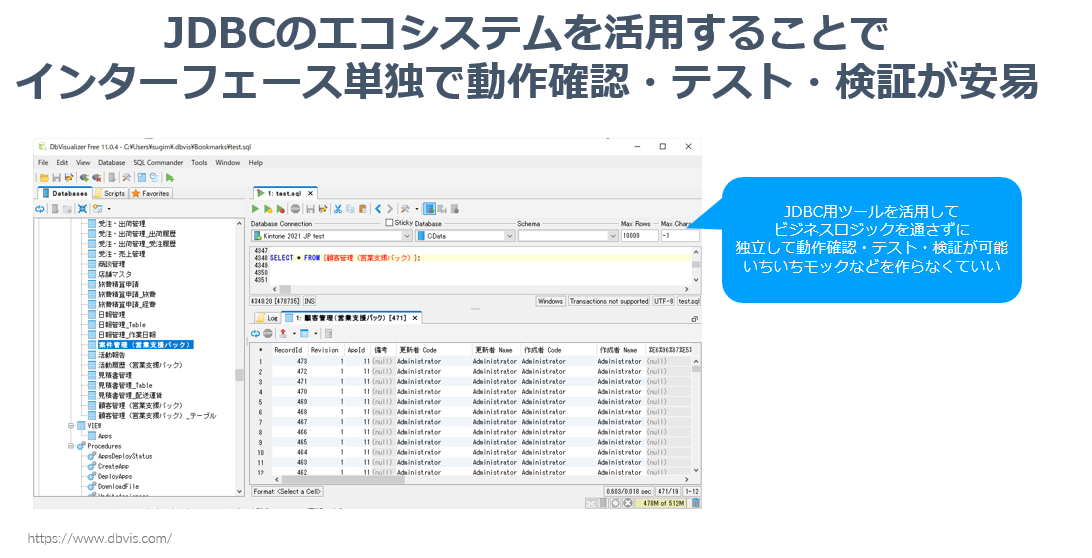
これはビルド・テスタビリティの確保にも現れていて、CData Sync本体とJDBCプラグイン側でデイリービルドが動いており、かつテストも独立して単体・結合・インターフェース・オンラインと組み込まれています。
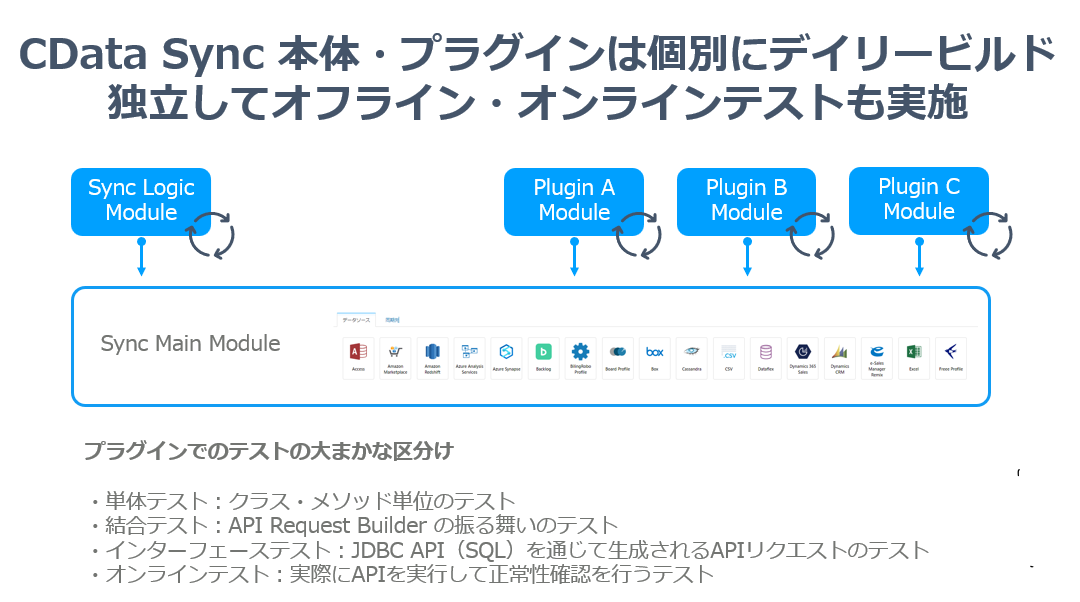
ちなみにインターフェースとしてのテストですが、以下のようにJDBCを扱うようにSQLを書いて、取得したデータセットをAssertで検証するという仕組みで実施しています。さらに内部ではリクエスト検証を行うダミーファイルを生成しており、実際のAPIとオンライン疎通することなくテストできるようになっていたりします。

と、ここまで華麗なお話ばかりを述べてきました。こういった工夫により、独立ビルド・開発性が担保されたわけですが、あとはひたすら泥臭いAPIへの追従です。
特に外部APIとインターフェースの機能の辻褄合わせは、特に気を使う部分ですね。
例えば、データを取得したいといっても、色んな取得方法がありますし、それをインターフェースに意識させずに内部で処理を隠蔽するのは、ユーザーエクスペリエンス的にも必須な要件です。
- GETで素直に取得できるパターン
- 特殊ページネーションパターン
- ジョブパターン(BigQuery)
さらに、Metadataを提供するために、適切な型を見極めるのも結構大変な作業ですね。
そもそもAPI仕様書に型が載っていないものも数多くありますし、数値や日付はどのように扱うのか気をつけなければいけません。

さらに難しいのはエラーハンドリングをどこまでインターフェース側でカバーするべきか?という点もありますね。特に数多くのAPIはAPI Limitを設けていたりするので、内部的に待機するべきなのか? エラーとしてクライアント側に伝えるべきなのか?といったハンドリングは常に悩ましいところです。
内容によってはクライアント側に伝えるべきではないエラーもありますよね。

このあたりをひたすら泥臭く定義しながら、API連携レイヤーのプラグインが保たれていたりします。
CData Sync の変遷
ちなみに、余談ですがリリース当初のCData Sync はビジネスロジックとプラグインという分け方が無く、密結合でした。ユーザーは使いたいAPIの数だけソフトウェアをインストールする必要があった
しかしながら、ビジネスロジックに修正が入ると、全部ビルドを作り直しをしなければいけない、さらにビジネスロジックサイド・インターフェースの影響範囲が広くなってしまう、というところから今のプラグインモデルが採用されました。
これにより、データソースの追加スピードや機能アップデートサイクルが安定して、今のデータソース数の爆発に繋がっています。
まとめ
さて、ここまでざっとCData としての取り組みを紹介してきましたが、やはり改めて認識しておきたいことは「不安定かつ多様なAPIと共存している」という点でしょう。
そしてこういった外部要因と共存しながら、ビジネスのスケールが求められており、そこでよりアプリケーションの作り方というのが重要になってきています。
API追従の痛み、衝撃、影響というのを最小化するアーキテクチャ、そしてそういったAPIへの追従を行いながらも、各チームが独立して機能追加・アップデート・ビルド・テスト・リリースまで行える体制が、組織としての、ビジネスとしてのスケールに繋がります。
一つのモジュールに関わる人数が増えれば増えるほど、密結合な部分が増えれば増えるほど、機能の追加・API Updateへの追従は重くなり、組織として、ビジネスとして、フレキシブルに動くことが難しくなってきます。
そこでぜひ改めて「インターフェース」という要素の重要性を意識してみてほしいと考えています。
JDBC をインターフェースで採用するというのは、なかなか他の会社にとってはハードルが高い部分が多いと思いますが、ぜひこういったポイントをヒントにAPI連携の充実に取り組んでみてはいかがでしょうか。
私達の取り組みが皆様のプロダクト開発・API連携のヒントになってもらえると嬉しいです。
おわりに
ちなみに CData Software Japan では絶賛採用を強化中です! 開発はUSがメインですが、国産SaaS APIへの連携も強化しているので、テクニカルサポートはもちろん、開発メンバーも募集しています!
グローバルにAPI連携を推し進める会社でぜひ一緒に働いてみませんか? カジュアル面談からでもOKです。
以下のリンクからどうおお気軽にご連絡ください!

補足:Web API Advent Calendar 2021
なお、今回の記事は Web API Advent Calendar 2021 1日目の記事でした!
以降もたくさんAPI関連ネタが投稿される予定なので、是非皆さんご覧 or ご参加ください!